Linux 系统调用函数fork、vfork、clone详解
1 fork
1.1 基本介绍
| |
描述
fork用于创建一个子进程,它与父进程的唯一区别在于其PID和PPID,以及资源利用设置为0。文件锁和挂起信号(指已经被内核发送给一个进程,但尚未被该进程处理的信号)不会被继承,其他和父进程几乎完全相同:会获得父进程的内存空间、栈、数据段、堆、打开的文件描述符、信号处理函数、进程优先级、环境变量等资源的副本。
返回值
成功时,在父进程中返回子进程的 PID,在子进程中返回 $0$。失败时,父进程返回 $-1$,不创建子进程,并适当设置 errno。
其中errno是一个全局变量,它用于表示最近一次系统调用或库函数调用产生的错误代码。当系统调用或库函数失败时,它们通常会设置 errno 以指示错误的原因。
以下是一些常见的 errno 错误代码及其含义:
- EAGAIN:资源暂时不可用,通常是因为达到了系统限制,如文件描述符或内存限制。
- ENOMEM:内存不足,无法分配请求的资源。
- EACCES:权限不足,无法访问某个资源。
- EINTR:系统调用被信号中断。
- EINVAL:无效的参数。
重点
fork() 函数创建的子进程会从父进程复制执行顺序。具体来说,子进程会从父进程复制当前的执行上下文,包括指令指针(instruction pointer)和寄存器的状态。这意味着子进程将从 fork() 系统调用之后的指令开始执行,与父进程在 fork() 之后应该执行的指令完全相同。因此,fork() 之后通常会有一个基于返回值的分支结构,以区分父进程和子进程的执行路径。
1.2 fork实例
####.1多个fork返回值
| |
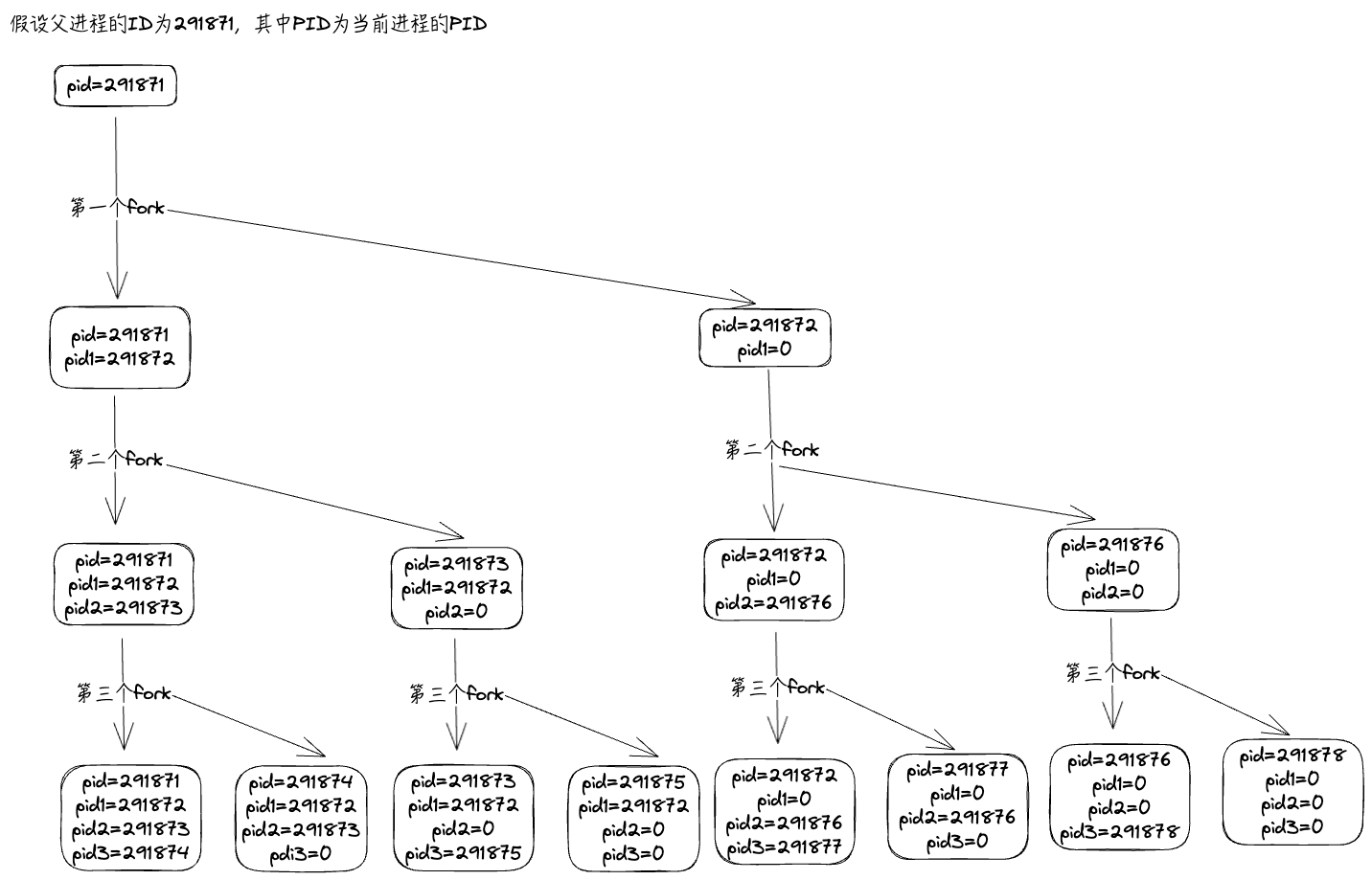
这段程序包含了三个 fork() 调用,每个 fork() 都会创建一个新的子进程。由于每次 fork() 调用都会导致进程数翻倍,所以总共会有$2^3=8$个进程 (包括最初的父进程)。每个进程都会打印出它的进程 ID (pid) 以及三个 fork() 调用的返回值 (pid1, pid2, pid3)。
得到的输出结果如下:
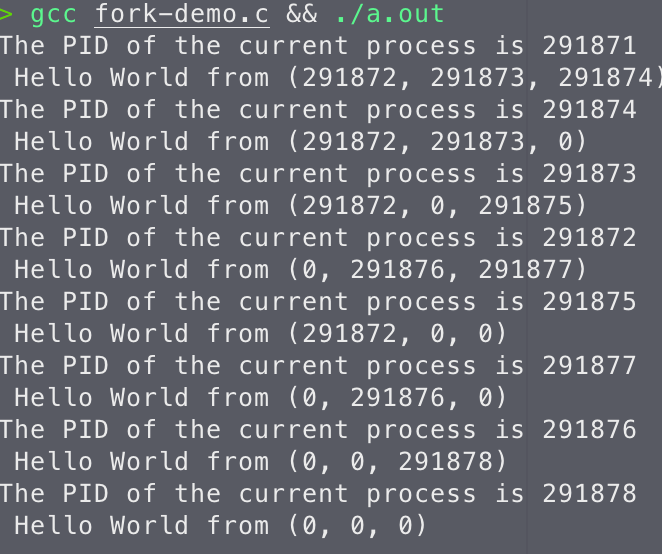
我们画个状态机来理解它们的输出,假设最初的父进程PID为291871:
1.2.1 C语言 fork与输出
| |
这段代码中,按我们的理解,第一次fork后有2个进程,然后一起执行printf输出,得到两个Hello,然后第二次fork后有4个进程,然后执行printf,得到四个Hello,则会有6个``Hello`,如下:

但是当我们将输出通过管道传给cat等命令时,会看到8个Hello:

这是因为标准输出一般是行缓冲的,碰到\n,缓冲区中的内容会被刷新,即输出到终端或文件中。这种缓冲方式的目的是为了提高效率,因为这样可以减少对磁盘 I/O 的调用次数。
如果标准输出被重定向到管道,它可能不再是行缓冲的,而是变为全缓冲的。这意味着缓冲区可能会在填满时刷新,而不是在每次遇到换行符时刷新。如果缓冲区足够大,以至于可以容纳所有的 Hello 输出,那么fork的时候子进程也会复制缓冲区,导致最后每个进程中的缓冲区都有2个Hello,最后输出为8个。
如果为了确保缓冲区在需要的时候被刷新,可以在 printf 调用之后显式地调用 fflush(stdout) 来刷新标准输出缓冲区。这样可以确保所有的输出都被立即写入,而不会受到缓冲行为的影响。
| |

1.2.2 fork 💣
| |
这段代码会无限循环地调用 fork() 函数,每次循环都会创建一个新进程。由于每次 fork() 调用都会成功创建一个新进程,而且这个新进程又会立即进入下一次循环并再次调用 fork(),因此进程的数量会以指数速度增长,很快就会耗尽系统的可用资源。
绝对不要在任何生产环境或您没有权限的任何系统上运行fork炸弹。
2 vfork
2.1 基本介绍
描述
1 2 3 4#include <sys/types.h> #include <unistd.h> pid_t vfork(void);vfork()系统调用用于创建一个子进程,与fork()类似,但它使用父进程的地址空间,而不是复制父进程的地址空间。vfork()调用后,父进程会阻塞,直到子进程调用exec函数或执行了 exit 函数。这是因为子进程需要独占父进程的地址空间,以确保数据一致性。一。在子进程调用exec函数或执行了exit函数之后,子进程将获得自己的内存空间。返回值
和
fork一致重点
vfork()创建的子进程会继承父进程的环境,但不会继承父进程的堆栈。- 在子进程执行这些
exec或exit操作之前,父进程和子进程可能会访问相同的内存地址,这可能导致数据竞争和不一致。 - 在
vfork()调用成功后,子进程应该立即调用exec函数或执行exit函数。如果在子进程中修改除了用于存储从vfork()返回值的pid_t类型变量之外的任何数据,或者从调用vfork()的函数返回,或在成功调用_exit()或exec()函数族中的一个函数之前调用其他任何函数,则行为是未定义的。这可能会导致程序崩溃或表现出不可预测的行为。 因此,使用vfork()时,必须确保子进程在调用exec函数或执行exit函数之前不执行任何可能影响共享内存的操作。 vfork()系统调用会阻塞父进程,直到子进程完成exec调用或exit调用。父进程不需要显式调用wait()或waitpid()来等待子进程结束。
2.2 验证vfork共享内存
| |
这个程序的目的是验证在 vfork() 之后,子进程和父进程是否共享内存。首先在父进程中分配一块内存 ,并将其初始化为字符 ‘A’。然后,父进程调用 vfork() 创建一个子进程。在子进程中,程序试图将内容修改为字符 ‘B’,并执行 execve()。在父进程中,程序检查缓冲区的内容是否被修改为字符 ‘B’,以验证内存是否被正确共享。
程序运行结果如下:

3 clone
3.1 基本介绍
描述
1 2 3 4#define _GNU_SOURCE #include <sched.h> int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, ... /* pid_t *parent_tid, void *tls, pid_t *child_tid */ );clone与fork类似,是用于创建新进程的系统调用,但clone提供了更精确的控制,可以确定在调用进程(父进程)和子进程之间共享哪些执行上下文的部分。例如,调用者可以控制两个进程是否共享虚拟地址空间、文件描述符表和信号处理程序表。这些系统调用还允许将新的子进程放置在单独的命名空间中。参数
fn是指向新进程要执行的函数的指针,这个函数接受一个 void* 参数,并返回一个 int 类型的值,这个返回值将被 clone 系统调用捕获,并作为子进程的退出状态;child_stack是新进程的堆栈地址,由于子进程和调用进程可能共享内存,因此子进程不可能与调用进程在同一堆栈中执行。调用进程必须为子堆栈设置内存空间,并将指向该空间的指针传递给clone()。flags可以设置新进程的属性(通过二进制位设置),包括是否与原进程共享地址空间(CLONE_VM)、是否共享文件描述符表(CLONE_FILES)、是否共享信号处理器(CLONE_SIGHAND)等等;int flags = CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND | CLONE_THREAD | CLONE_SYSVSEM | CLONE_SETTLS;标志 含义 CLONE_PARENT 创建的子进程的父进程是调用者的父进程,新进程与创建它的进程成了“兄弟”而不是“父子” CLONE_FS 子进程与父进程共享相同的文件系统,包括root、当前目录、umask CLONE_FILES 子进程与父进程共享相同的文件描述符(file descriptor)表 CLONE_NEWNS 在新的namespace启动子进程,namespace描述了进程的文件hierarchy CLONE_SIGHAND 子进程与父进程共享相同的信号处理(signal handler)表 CLONE_PTRACE 若父进程被trace,子进程也被trace CLONE_VFORK 父进程被挂起,直至子进程释放虚拟内存资源 CLONE_VM 子进程与父进程运行于相同的内存空间 CLONE_PID 子进程在创建时PID与父进程一致 CLONE_THREAD Linux 2.4中增加以支持POSIX线程标准,子进程与父进程共享相同的线程群 arg是传递给新进程的参数;可选参数,包括
pid_t *parent_tid等。
返回值
成功时,在父进程中返回子进程的 PID。失败时,父进程返回 $-1$,不创建子进程,并适当设置
errno。重点
clone可以创建新的进程或线程,Linux创建线程使用的系统调用就是clone。而fork和vfork只能创建进程。这意味着clone可以在单个进程中创建多个线程,而fork则总是创建一个新的进程。clone提供比fork和vfork更多的选项,可以指定子进程或线程的堆栈、信号处理、权限等。clone的使用比fork和vfork更复杂,需要正确设置 flags、child_stack、parent_pidptr、ptr、stack_size 和 tls 等参数。
3.2 clone使用
| |
运行:gcc clone-example.c && ./a.out 5,其中5为nproc,表示要创建的进程数。
运行结果如下:

相关内容
- Linux 系统调用函数fork、vfork、clone详解
- Linux用户和用户组教程
- 解决Linux系统centos7的开机报错:Welcome to Emergency Mode
- Linux常用命令、管道、环境变量
- Linux常用文件管理命令
 支付宝
支付宝 微信
微信