多级反馈队列
1 Note/Translation
基本规则
MLFQ有许多不同的队列,每个队列分配了不同的优先级。在任何给定时间,准备运行的作业都位于单个队列上。 MLFQ 使用优先级来决定在给定时间应运行哪个作业:选择运行具有较高优先级的作业(即较高队列上的作业)。当然,一个队列上可能有多个作业,即具有相同的优先级,这种情况则对这些工作使用RR调度。则MLFQ基本规则如下:
- $\text{Rule}\space1:\text{If Priority(A)>Priority(B),A runs (B doesn’t).}$
- $\text{Rule}\space1:\text{If Priority(A)=Priority(B),A and B run in RR.}$
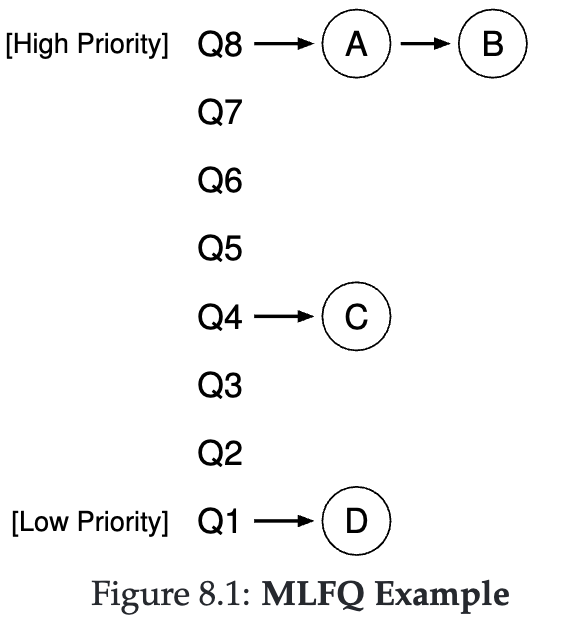
MLFQ例子
如果我们要展示给定时刻队列的样子,我们可能会看到如下所示的内容(图 8.1)。图中,两个作业(A 和 B)的优先级最高,作业 C 处于中间,作业 D 的优先级最低。鉴于我们目前对 MLFQ 工作原理的了解,调度程序只会在 A 和 B 之间交替时间片,因为它们是系统中优先级最高的作业;可怜的工作 C 和 D 根本无法运行!
尝试#1:怎么改变作业的优先级
现在,我们必须决定 MLFQ 将如何在作业的生命周期内更改作业的优先级(以及它所在的队列)。为此,我们必须牢记我们的工作负载:短期运行的交互式作业(可能经常放弃 CPU),以及一些需要大量 CPU 时间但运行时间较长的“CPU 密集型”作业。其中响应时间并不重要。这是我们对优先级调整算法的第一次尝试:
- $\text{Rule 3: When a job enters the system, it is placed at the highest priority (the topmost queue).}$
- $\text{Rule 4a: If a job uses up an entire time slice while running, its pri- ority is reduced (i.e., it moves down one queue).}$
- $\text{Rule 4b: If a job gives up the CPU before the time slice is up, it stays at the same priority level.}$
例子#1.1:单个长时间运行的作业
首先,我们来看看当系统中有一项长期运行的工作时会发生什么情况。下图显示了在三队列调度程序中该作业随时间发生的变化。
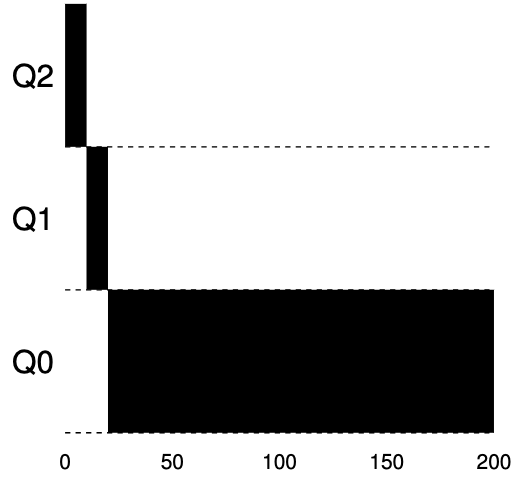
如示例所示,作业以最高优先级(Q2)进入。经过 $\text{10ms}$ 的单个时间片后,调度程序将作业的优先级降低了一个,因此作业的优先级为 Q1。在 Q1 上运行一个时间片后,作业最终被降到系统中的最低优先级(Q0),并保持不变。
例子#1.2:加入一个短作业
在这个例子中,有两个作业:A是一个长期运行的CPU密集型作业,B是一个短期运行的交互作业。假设A已经运行了一段时间,然后B才到达,这样会发生什么?MLFQ是否会近似于B的SJF?
如下图所示,A(黑色显示)在最低优先级队列中运行(任何长期运行的 CPU 密集型作业都是如此);B(灰色显示)在 T = 100 时到达,因此会插入到最高队列,由于其运行时间很短(仅20ms),B 在到达底层队列之前完成,分两个时间片;然后 A 恢复运行(低优先级)。
从这个例子中,你有望理解算法的一个主要目标:因为它不知道一项作业是短作业还是长期作业,所以它首先假定它可能是短作业,从而给予该作业高优先级。如果它确实是短作业,它就会快速运行并完成;如果它不是短作业,它就会在队列中缓慢移动,从而很快证明自己是一个长期运行的更类似批处理的进程。通过这种方式,MLFQ 近似于 SJF。
例子#1.3:关于I/O
如上文规则 4b 所述,如果进程在用完其时间片之前放弃了处理器,我们会将其保持在相同的优先级。这条规则的用意很简单:例如,如果一个交互式作业正在进行大量的 I/O(比如等待键盘或鼠标的用户输入),那么它就会在其时间片完成之前放弃 CPU;在这种情况下,我们不希望惩罚该作业,因此只需将其保持在同一优先级即可。
下图举例说明了这种方法的工作原理,交互式作业 B(灰色显示)只需要 CPU 1 ms,然后执行 I/O,与长期运行的批处理作业 A(黑色显示)争夺 CPU。MLFQ 方法将 B 保持在最高优先级,因为 B 一直在释放 CPU;如果 B 是交互式作业,MLFQ 将进一步实现快速运行交互式作业的目标。
我们现在设计的MLFQ存在的问题
这样,我们就有了一个基本的 MLFQ。它似乎做得相当不错,在长时间运行的作业之间公平地共享 CPU,并让短时间或 I/O 密集型交互式作业快速运行。遗憾的是,我们迄今为止开发的方法存在严重缺陷。
- 饥饿问题:如果系统存在太多交互作业,它们将会共同消耗所有CPU时间,这样长时间运行的作业将不会获得任何CPU时间(即饥饿)。
- 欺骗调度程序:聪明的用户可以重写程序,玩弄调度程序。即是指偷偷摸摸地欺骗调度程序,让调度程序给你分配更多的资源。我们所描述的算法很容易受到以下攻击:在时间片结束前,进行一次 I/O 操作(对某个你并不关心的文件),从而放弃 CPU;这样做可以让你保持在同一队列中,从而获得更多的 CPU 时间。如果操作得当(例如,运行 99% 的时间片后才放弃 CPU),作业几乎可以垄断 CPU。
- 程序行为改变:一个程序可能会随着时间的推移而改变其行为;原来的 CPU 约束可能会过渡到交互阶段。采用我们目前的方法,这样的作业就会倒霉,不会像系统中的其他交互式作业一样得到处理。
尝试#2:优先级提升
让我们试着改变规则,看看能否避免 “饥饿 “问题。为了保证占用 CPU 的作业能取得一些进展(即使进展不大),我们可以做些什么?简单来说,就是定期提升系统中所有作业的优先级。实现这一点的方法有很多,但我们只需做一件简单的事:把所有作业都扔到最上面的队列中;因此,我们需要一条新规则:
- $\text{Rule 5: After some time period S, move all the jobs in the system to the topmost queue.}$
我们的新规则同时解决了两个问题。首先,保证了进程不会饥饿:作业排在队列的最前面,就能与其他高优先级作业以循环方式共享 CPU,从而最终获得服务。其次,如果受 CPU 限制的作业已开始交互,调度程序会在其获得优先级提升后对其进行适当处理。
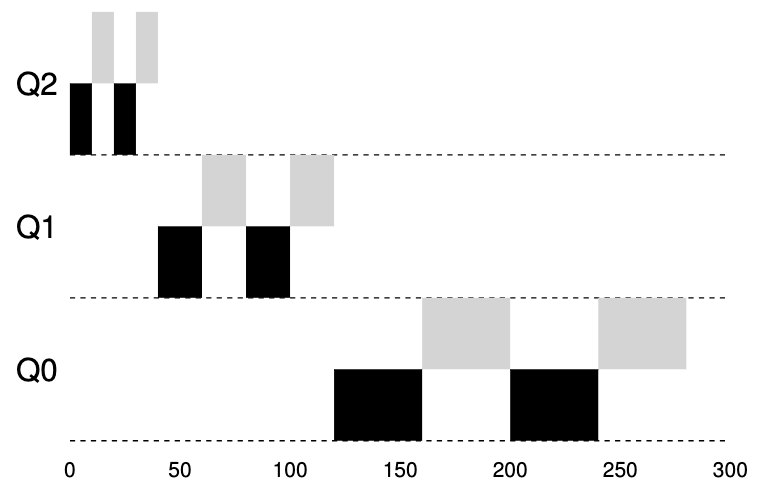
例子#2.1:竞争CPU
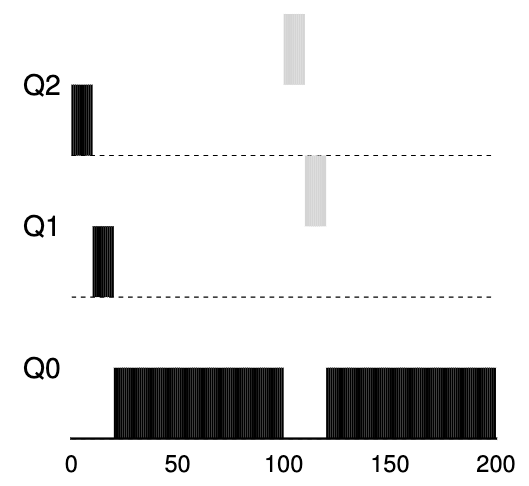
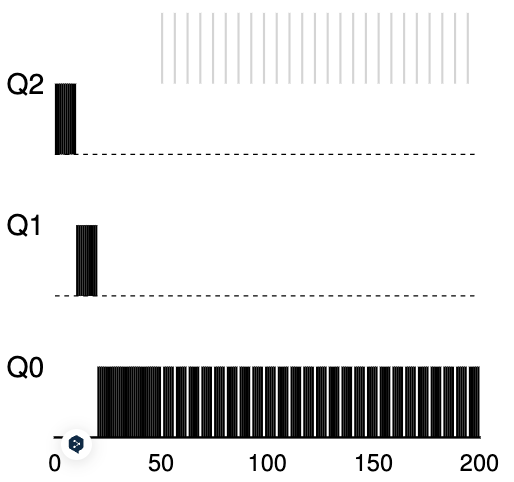
在这种情况下,我们仅展示一个长时间运行的作业与两个短时间运行的交互式作业竞争 CPU 时的行为。下图显示了两个图表。在左边,没有优先级提升,因此一旦两个短期作业到达,长期运行的作业就会陷入饥饿;右边,每 50 毫秒就有一次优先级提升(这个值可能太小,但这里用于示例),因此我们至少保证长时间运行的作业会取得一些进展,提升到每 50 毫秒设置一次最高优先级,从而定期运行。
-and-With(right)-Priority-Boost.png)
当然,增加时间段S会带来一个明显的问题:S应该设置为什么? John Ousterhout,一位受人尊敬的系统研究员 ,过去常常将系统中的此类值称为“巫术常量”,因为它们似乎需要某种形式的黑魔法才能正确设置它们。不幸的是,S有那种味道。如果设置得太高,长时间运行的作业可能会陷入困境;太低,交互式作业可能无法获得适当的 CPU 份额。
尝试#3:更好的计算
现在,我们还有一个问题要解决:如何防止调度程序被玩弄?正如你可能已经猜到的,真正的罪魁祸首是Rule 4a 和 4b,它们允许作业在时间片到期前放弃 CPU,从而保留其优先级。那么我们该怎么办呢?解决办法是在 MLFQ 的每一级更好地计算 CPU 时间。调度程序不应该忘记进程在特定级别上使用了多少时间片,而应该进行跟踪;一旦进程用完了分配的时间片,就会被降级到下一个优先级队列。至于进程是在一个长的时间段内使用时间片,还是在许多小的时间段内使用时间片,这并不重要。因此,我们将规则 4a 和 4b 重写为以下单一规则:
- $\text{Rule 4: Once a job uses up its time allotment at a given level (re- gardless of how many times it has given up the CPU), its priority is reduced (i.e., it moves down one queue).}$
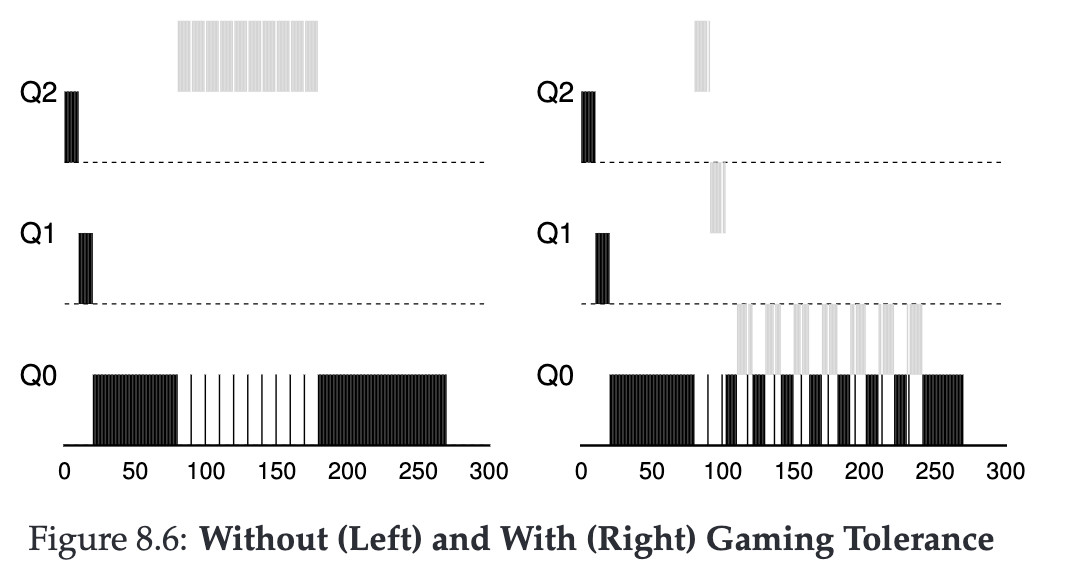
例子#3.1:旧规则和新规则对比
下图显示了当工作负载试图利用旧规则 4a 和 4b(左侧)以及新的反玩弄规则 4 来玩弄调度程序时会发生的情况。如果没有任何防止玩弄的保护措施,进程可以在时间片结束前发出 I/O,从而支配 CPU 时间。有了这种保护措施,无论进程的 I/O 行为如何,它都会在队列中缓慢移动,从而无法获得不公平的 CPU 占有率。
调整 MLFQ 及其他问题
MLFQ 调度还存在其他一些问题。一个大问题是如何为这样的调度器设置参数。例如,应该有多少个队列?每个队列的时间片应该有多大?为了避免饥饿并考虑到行为的变化,应该多久提升一次优先级?这些问题都没有简单的答案,因此只有在工作负载方面积累一定的经验,然后对调度程序进行调整,才能取得令人满意的平衡。
例如,大多数 MLFQ 变体都允许在不同队列中使用不同的时间片长度。高优先级队列的时间片通常较短;毕竟它们由交互式作业组成,因此在它们之间快速交替是合理的(例如 10 毫秒或更少)。相比之下,低优先级队列包含的是占用 CPU 的长期运行作业;因此,较长的时间片(如 100 毫秒)也很有效。下图显示了一个例子,其中两个作业在最高队列运行 20 毫秒(时间片为 10 毫秒),在中间队列运行 40 毫秒(时间片为 20 毫秒),在最低队列运行 40 毫秒。
Solaris MLFQ 实现——分时调度类(TS)——特别容易配置;它提供了一组表,可以准确确定进程的优先级在其整个生命周期中如何更改、每个时间片的长度以及提高作业优先级的频率;管理员可以修改该表以使调度程序以不同的方式运行。该表的默认值为 60 个队列,时间片长度从 20 毫秒(最高优先级)缓慢增加到几百毫秒(最低),并且优先级大约每 1 秒左右提升一次。
其他 MLFQ 调度器并不使用本章所述的表格或精确规则,而是使用数学公式来调整优先级。例如,FreeBSD 调度器(4.3 版)使用一个公式来计算作业当前的优先级,该公式基于进程使用了多少 CPU ;此外,使用率会随着时间的推移而衰减,从而以与本文所述不同的方式提供所需的优先级提升。最后,许多调度器还有一些你可能会遇到的其他功能。例如,有些调度器为操作系统工作保留最高优先级;因此,典型的用户作业永远无法获得系统中的最高优先级。有些系统还允许用户通过一些建议来帮助设置优先级;例如,通过使用命令行实用程序 nice,你可以(在一定程度上)提高或降低作业的优先级,从而增加或减少它在任何特定时间运行的机会。
MLFQ总结
我们已经描述了多级反馈队列(MLFQ)的调度方法。希望你现在能明白它为什么叫这个名字:它有多级队列,并使用反馈来确定给定作业的优先级。历史是它的指南:关注作业在一段时间内的表现,并相应地处理它们。在本章中,MLFQ 规则的精炼集在此重现,供大家欣赏:
- $\text{Rule 1: If Priority(A) > Priority(B), A runs (B doesn’t).}$
- $\text{Rule 2: If Priority(A) = Priority(B), A and B run in round-robin fash- ion using the time slice (quantum length) of the given queue.}$
- $\text{Rule 3: When a job enters the system, it is placed at the highest priority (the topmost queue).}$
- $\text{Rule 4: Once a job uses up its time allotment at a given level (re- gardless of how many times it has given up the CPU), its priority is reduced (i.e., it moves down one queue).}$
- $\text{Rule 5: After some time period S, move all the jobs in the system to the topmost queue.}$
MLFQ 很有趣,原因如下:它不要求先验了解作业的性质,而是观察作业的执行情况并相应地确定其优先级。通过这种方式,它成功地实现了两全其美:它可以为短时间运行的交互式作业提供出色的整体性能(类似于 SJF/STCF),并且对于长时间运行的 CPU 密集型工作负载来说,它是公平的并取得进步。因此,许多系统,包括 BSD UNIX 衍生系统 、Solaris 以及 Windows NT 和后续的 Windows 操作系统,都使用某种形式的 MLFQ 作为其基本调度程序。

2 Program Explanation
这个程序 mlfq.py 允许您查看本章中介绍的 MLFQ 调度程序的行为方式。和以前一样,您可以使用它来使用随机种子为自己生成问题,或者使用它构建一个精心设计的实验,以了解 MLFQ 在不同情况下的工作原理。要运行该程序,请键入:
| |
使用参数-h查看选项帮助:
| |
使用模拟器有几种不同的方法,一种方法是生成一些随机作业,然后看看您是否可以弄清楚它们在给定 MLFQ 调度程序的情况下将如何表现。例如,如果您想创建随机生成的三作业工作负载,您只需运行
| |
这会在具有多个默认设置的默认数量的队列上生成三个作业(根据指定)的随机工作负载。如果您使用 (-c) 上的求解选项再次运行,您将看到与上面相同的打印输出,以及以下内容:
| |
该跟踪以毫秒为单位准确显示了调度程序决定执行的操作。在此示例中,它首先运行作业 0 7 毫秒,直到作业 0 发出 I/O;这是完全可以预测的,因为作业 0 的 I/O 频率设置为 7 ms,这意味着它每运行 7 ms,就会发出一个 I/O 并等待其完成后再继续。此时,调度程序切换到作业 1,该作业在发出 I/O 之前仅运行 2 毫秒。调度程序以这种方式打印整个执行跟踪,最后还计算每个作业的响应时间和周转时间以及平均值。
您还可以控制模拟的各个其他方面。例如,您可以指定系统中希望有多少个队列 (-n) 以及所有这些队列的时间片长度应该是多少 (-q);如果您想要更多的控制和每个队列不同的时间片长度,您可以使用 -Q 指定每个队列的时间片的长度,例如, -Q 10,20,30] 模拟具有三个队列的调度程序,最高优先级队列具有 10 毫秒时间片,次高优先级队列具有 20 毫秒时间片,低优先级队列具有 30 毫秒时间片。
您也可以单独控制每个队列的时间分配量。可以使用 -a 对所有队列进行设置,或使用 -A 对每个队列进行设置,例如 -A 20,40,60 将每个队列的时间分配分别设置为 20ms、40ms 和 60ms。请注意,虽然本章讨论的是时间方面的分配,但这里是根据时间片的数量来完成的,即,如果给定队列的时间片长度为 10 毫秒,并且分配为 2,则作业可以运行在优先级下降之前,在该队列级别持续 2 个时间片(20 毫秒)。
如果您随机生成作业,您还可以控制它们运行的时间 (-m) 或它们生成 I/O 的频率 (-M)。但是,如果您希望更多地控制系统中运行的作业的确切特征,则可以使用 -l(小写 L)或 –jlist,它允许您指定要模拟的确切作业集。该列表的格式为:x1,y1,z1:x2,y2,z2:… 其中 x 是作业的开始时间,y 是运行时间(即需要多少 CPU 时间),z I/O 频率(即运行 z ms 后,作业发出 I/O;如果 z 为 0,则不发出 I/O)。
例如,如果您想重新创建图 8.3 中的示例,您可以指定一个作业列表,如下所示:
python mlfq.py --jlist 0,180,0:100,20,0 -q 10
以这种方式运行模拟器会创建一个三级 MLFQ,每个级别都有 10 毫秒的时间片。创建了两个作业:作业 0 在时间 0 启动,总共运行 180 毫秒,并且从不发出 I/O;作业 1 从 100 毫秒开始,仅需要 20 毫秒的 CPU 时间即可完成,而且从不发出 I/O。
最后,还有另外三个令人感兴趣的参数。 -B 参数如果设置为非零值,则在调用时每 N 毫秒将所有作业提升到最高优先级队列:
调度程序使用此功能来避免饥饿,如本章中所讨论的。但是,默认情况下它是关闭的。
-S 标志调用旧规则 4a 和 4b,这意味着如果作业在完成其时间片之前发出 I/O,则当它恢复执行时,它将返回到相同的优先级队列,并且其完整分配完好无损。这可以玩弄调度器。
最后,您可以使用 -i 标志轻松更改 I/O 持续的时间。默认情况下,在此简单模型中,每个 I/O 需要 5 毫秒的固定时间或使用此标志设置的任何时间。
您还可以使用 -I 标志尝试将刚刚完成 I/O 的作业移动到它们所在队列的头部还是后面。看看吧,很好玩!
3 QA
- 仅使用两个作业和两个队列运行一些随机生成的问题;计算每个的 MLFQ 执行轨迹。通过限制每个作业的长度和关闭 I/O 让您的生活更轻松。
例子:
python mlfq.py -n 2 -j 2 -m 20 -M 0 -s 66Job List: Job 0: startTime 0 - runTime 2 - ioFreq 0 Job 1: startTime 0 - runTime 5 - ioFreq 0 Execution Trace: [ time 0 ] JOB BEGINS by JOB 0 [ time 0 ] JOB BEGINS by JOB 1 [ time 0 ] Run JOB 0 at PRIORITY 1 [ TICKS 9 ALLOT 1 TIME 1 (of 2) ] [ time 1 ] Run JOB 0 at PRIORITY 1 [ TICKS 8 ALLOT 1 TIME 0 (of 2) ] [ time 2 ] FINISHED JOB 0 [ time 2 ] Run JOB 1 at PRIORITY 1 [ TICKS 9 ALLOT 1 TIME 4 (of 5) ] [ time 3 ] Run JOB 1 at PRIORITY 1 [ TICKS 8 ALLOT 1 TIME 3 (of 5) ] [ time 4 ] Run JOB 1 at PRIORITY 1 [ TICKS 7 ALLOT 1 TIME 2 (of 5) ] [ time 5 ] Run JOB 1 at PRIORITY 1 [ TICKS 6 ALLOT 1 TIME 1 (of 5) ] [ time 6 ] Run JOB 1 at PRIORITY 1 [ TICKS 5 ALLOT 1 TIME 0 (of 5) ] [ time 7 ] FINISHED JOB 1 Final statistics: Job 0: startTime 0 - response 0 - turnaround 2 Job 1: startTime 0 - response 2 - turnaround 7 Avg 1: startTime n/a - response 1.00 - turnaround 4.50 - 您将如何运行调度程序来重现本章中的每个示例?
// Figure 8.2 Long-running Job Over Time
>python mlfq.py -n 3 -q 10 -l 0,200,0 -c// Figure 8.3 Along Came An Interactive Job>python mlfq.py -n 3 -q 10 -l 0,180,0:100,20,0 -c// Figure 8.4 A Mixed I/O-intensive and CPU-intensive Workload>python mlfq.py -n 3 -q 10 -l 0,175,0:50,25,1 -i 5 -S -c// Figure 8.5 without priority boost>python mlfq.py -n 3 -q 10 -l 0,120,0:100,50,1:100,50,1 -i 1 -S -c// Figure 8.5 with priority boostpython mlfq.py -n 3 -q 10 -l 0,120,0:100,50,1:100,50,1 -i 1 -S -B 50 -c// Figure 8.6 without gaming tolerance> python mlfq.py -n 3 -q 10 -i 1 -S -l 0,200,0:80,100,9 -c// Figure 8.6 with gaming tolerancepython mlfq.py -n 3 -q 10 -i 1 -l 0,200,0:80,100,9 -c// Figure 8.7 Lower Priority, Longer Quantapython mlfq.py -n 3 -a 2 -Q 10,20,40 -l 0,200,0:0,200,0 -c - 如何配置调度程序参数以使其像循环调度程序一样运行?
同一队列上的作业是按时间分片的,因此答案是只有一个队列。
- 使用两个作业和调度程序参数制作一个工作负载,以便一个作业利用旧的规则 4a 和 4b(使用 -S 参数打开)来欺骗调度程序并在特定的情况下获得 99% 的 CPU 占用率时间间隔。
首先,使用 -i 将 I/O 时间设置为 1,然后确保 CPU hog 在 100 个点击时间片长度的第 99 个点击时调用 I/O 操作。另外,包含 -I 标志以确保 CPU 占用者在 I/O 请求完成时重新获得控制权:
python mlfq.py -S -i 1 -l 0,297,99:0,60,0 -q 100 -n 3 -I -c - 给定一个系统,其最高队列的时间片长度为 10 毫秒,您需要多久将作业提升回最高优先级(使用 -B 标志)才能保证单个长时间运行的作业(并且可能会饥饿)作业至少获得 5% 的 CPU 资源?
如果每 10 毫秒就有一个新的 10 毫秒长作业到达 - 如图 8.5(左)所示,每 200 个时钟周期提升可确保长进程将运行 10/200 个 CPU 周期 = 5%。
- 调度中出现的一个问题是在队列的哪一端添加刚刚完成 I/O 的作业; -I 参数更改此调度模拟器的此行为。尝试一些工作负载,看看是否可以看到此参数的效果。使用
1 2python mlfq.py -n 2 -q 10 -l 0,50,0:0,50,11 -i 1 -S -c python mlfq.py -n 2 -q 10 -l 0,50,0:0,50,11 -i 1 -S -I -c-I的周转时间下降了很多。
相关内容
 支付宝
支付宝 微信
微信