多CPU调度
1 多处理器架构
要理解围绕多处理器调度的新问题,我们必须了解单 CPU 硬件与多 CPU 硬件之间的一个新的根本区别。这种区别主要围绕硬件缓存的使用(如下图所示),以及多个处理器之间共享数据的具体方式。
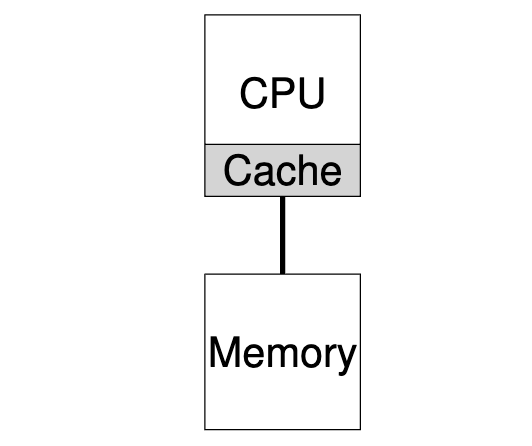
在单个CPU系统中,硬件缓存(Cache)的层次结构通常有助于处理器更快地运行程序。Cache是一种小型快速存储器,(一般来说)保存系统主存储器中常用数据的副本。相比之下,主存储器保存了所有数据,但访问这个较大的内存时速度较慢。通过将频繁访问的数据保存在高速缓存中,系统可以让又大又慢的内存看起来很快。
例如,一个程序要从内存中获取一个值,需要发出一条显式加载指令,而一个简单的系统只有一个 CPU;CPU 有一个小缓存(比如 64 KB)和一个大主存。程序首次发出加载指令时,数据位于主内存中,因此需要很长时间(可能是几十纳秒,甚至几百纳秒)才能获取。处理器预计数据可能会被重复使用,因此会将加载数据的副本放入 CPU 缓存。如果程序稍后再次提取相同的数据项,CPU 会首先检查缓存中是否有该数据项;如果在缓存中找到了该数据项,提取数据的速度就会快得多(比如只需几纳秒),从而加快程序的运行速度。
因此,缓存是以局部性概念为基础的,局部性有两种:时间局部性和空间局部性。时间局部性背后的理念是,当一个数据被访问时,它很可能在不久的将来再次被访问;想象一下变量甚至指令本身在循环中被反复访问的情景。空间局部性背后的理念是,如果程序访问了地址为 x 的数据项,那么它很可能也会访问 x 附近的数据项;在这里,可以想象程序在数组中流水作业,或者指令被一条接一条地执行。由于许多程序都存在这些类型的局部性,因此硬件系统可以很好地猜测哪些数据应放入高速缓存,从而很好地工作。
但如果在一个系统中使用多个处理器和一个共享主存储器,如下图所示,会发生什么情况?
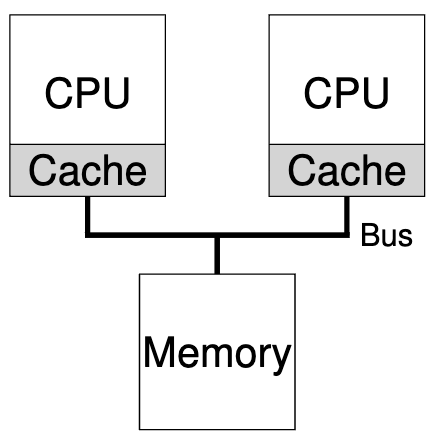
事实证明,多 CPU 缓存要复杂得多。如下图所示,假设在 CPU 1 上运行的程序读取并更新了地址 A 上的一个数据项(值为 D);由于 CPU 1 的缓存中没有该数据,系统会从主存中获取该数据项,并得到值 D。然后假设操作系统决定停止运行程序,并将其移至 CPU 2。然后程序重新读取地址 A 处的值,发现缓存没有这样的数据 ,因此系统从主内存中获取值,并获取旧值 D 而不是正确值 D ′。这个普遍问题称为缓存一致性问题。

硬件提供了基本的解决方案:通过监控内存访问,硬件可以确保基本上 “正确的事情 “发生了,并且单个共享内存的视图得以保留。在基于总线的系统(如上所述)上实现这一点的一种方法是使用一种称为总线窥探(bus snooping)的古老技术;每个高速缓存通过观察连接内存和主内存的总线来关注内存更新。当 CPU 看到其缓存中的数据项有更新时,就会注意到这一变化,要么使其副本失效(即从自己的缓存中删除),要么进行更新(即把新值也放入自己的缓存中)。如上文述,回写缓存会使这一过程变得更加复杂(因为写入主内存的内容要到稍后才能看到),但你可以想象一下基本方案是如何工作的。
2 不要忘记同步
既然缓存为提供一致性做了所有这些工作,那么程序(或操作系统本身)在访问共享数据时还需要担心什么吗?答案是肯定的,程序(或操作系统)在访问共享数据时仍然需要考虑一些问题:
- 竞争条件(Race Conditions):即当多个进程或线程试图同时访问共享资源时可能出现的问题。
- 原子性操作:某些操作可能涉及多个步骤,需要确保这些步骤的执行是原子的。
- 内存栅栏和同步:在某些情况下,需要使用内存栅栏(memory barriers)或者同步机制来确保在不同处理器上的操作执行顺序。这是因为缓存一致性只保证了缓存之间和缓存与内存之间的一致性,而不是对所有指令的执行顺序做出保证。
在跨 CPU 访问(尤其是更新)共享数据项或结构时,应使用互斥原语(如锁)来保证正确性(其他方法,如构建无锁数据结构,比较复杂,只能偶尔使用)。例如,假设多个 CPU 同时访问一个共享队列。如果没有锁,即使使用了底层一致性协议,并发添加或删除队列中的元素也无法达到预期效果;我们需要用锁将数据结构原子更新到新状态。
为了更具体地说明这一点,我们可以看下面这段用于从共享链表中删除一个元素的代码序列。想象一下,如果两个 CPU 上的线程同时进入这个例程。如果线程 1 执行了第一行,它的 tmp 变量中将存储 head 的当前值;如果线程 2 也执行了第一行,它的私有 tmp 变量中也将存储 head 的相同值(tmp 在栈中分配,因此每个线程都有自己的私有存储空间)。这样,每个线程就不会从列表头部删除一个元素了,而是尝试删除这相同的头元素,就会导致各种问题(例如第 4 行中试图对头部元素进行双重释放,以及可能两次返回相同的数据值)。
| |
当然,解决方案是通过锁定来使此类例程正确。在这种情况下,分配一个简单的互斥体(例如,pthread mutex t m;),然后在例程的开头添加一个 lock(&m) 并在末尾添加一个 unlock(&m) 将解决问题,确保代码能够执行如预期的。不幸的是,正如我们将看到的,这种方法并非没有问题,特别是在性能方面。具体来说,随着CPU数量的增加,对同步共享数据结构的访问变得相当慢。
| |
3 最后一个问题:缓存亲和性
最后一个问题是在构建多处理器缓存调度程序时出现的,称为缓存亲和性。这个概念很简单:进程在特定 CPU 上运行时,会在 CPU 的缓存(和 TLB)中构建相当多的状态。下一次进程运行时,在同一个 CPU 上运行它通常是有利的,因为如果它的某些状态已经存在于该 CPU 上的缓存中,那么它会运行得更快。相反,如果每次在不同的 CPU 上运行一个进程,则该进程的性能会更差,因为每次运行时都必须重新加载状态(注意,由于硬件的缓存一致性协议,它可以在不同的 CPU 上正常运行)。因此,多处理器调度程序在做出调度决策时应考虑缓存关联性,如果可能的话,可能更愿意将进程保留在同一 CPU 上。
4 Single queue Multiprocessor Scheduling (SQMS)
有了这个背景,我们现在讨论如何为多处理器系统构建调度程序。最基本的方法是简单地重用单处理器调度的基本框架,将所有需要调度的作业放入单个队列中;我们将此称为单队列多处理器调度或简称为 SQMS。这种方法的优点是简单;不需要太多工作就可以采用现有策略来选择接下来运行的最佳作业,并将其调整为在多个 CPU 上工作(例如,如果有两个 CPU,它可能会选择最好的两个作业来运行) 。
然而,SQMS 也有明显的缺点。
第一个问题是缺乏可扩展性。为了确保调度程序在多个 CPU 上正常工作,开发人员将在代码中插入某种形式的锁,如上所述。锁确保当 SQMS 代码访问单个队列(例如,查找下一个要运行的作业)时,会出现正确的结果。但锁会大大降低性能,尤其是当系统中的 CPU 数量增加。随着对单个锁的争夺增加,系统花在锁开销上的时间越来越多,而花在系统本应完成的工作上的时间却越来越少。
SQMS 的第二个主要问题是缓存亲和性。例如,假设我们有五个作业(A、B、C、D、E)和四个处理器。因此,我们的调度队列看起来是这样的:

随着时间的推移,假设每个作业运行一个时间片,然后选择另一个作业,下面是一个可能的跨 CPU 作业时间表:

由于每个 CPU 只需从全局共享队列中选择下一个要运行的作业,因此每个作业最终都会在 CPU 之间来回跳转,这与缓存亲和性的观点恰恰相反。
为了解决这个问题,大多数 SQMS 调度器都包含某种亲和性机制,以尽可能使进程更有可能继续在同一 CPU 上运行。具体来说,调度器可能会为某些作业提供亲和性,但会移动其他作业以平衡负载。例如,设想同样的五个工作调度如下:

在这种安排下,作业 A 到 D 不会跨处理器迁移,只有作业 E 会从 CPU 迁移到 CPU,从而保留了大部分的亲和性。然后,你可以决定在下一次迁移时迁移不同的作业,从而实现某种亲和性公平性。不过,实施这样的方案可能会很复杂。因此,我们可以看到 SQMS 方法有其优点和缺点。对于现有的单 CPU 调度器(顾名思义,它只有一个队列)来说,它可以直接实施。但是,它的扩展性不佳(由于同步开销),而且不能轻易保留高速缓存亲和性。
5 Multi-queue Multiprocessor Scheduling (MQMS)
由于单队列调度器所带来的问题,一些系统选择了多队列,例如每个 CPU 一个队列。我们称这种方法为多队列多处理器调度(或 MQMS)。
在 MQMS 中,我们的基本调度框架由多个调度队列组成。每个队列都可能遵循特定的调度规则,如循环调度(RR),当然也可以使用任何算法。当作业进入系统时,会根据某种启发式(如随机,或挑选作业数量少于其他队列的队列),将其恰好置于一个调度队列中。然后,它基本上被独立调度,从而避免了单队列方法中的信息共享和同步问题。
例如,假设系统中只有两个 CPU(CPU 0 和 CPU 1),有若干作业进入系统:例如 A、B、C 和 D。鉴于每个 CPU 现在都有一个调度队列,操作系统必须决定将每个作业放入哪个队列。操作系统可能会这样做:

根据队列调度策略的不同,现在每个 CPU 在决定运行什么作业时都有两个作业可供选择。例如,如果采用循环调度,系统可能会产生如下调度:

与 SQMS 相比,MQMS 有一个明显的优势,那就是它本质上更具可扩展性。随着 CPU 数量的增加,队列的数量也会增加,因此锁和缓存争用不会成为核心问题。此外,MQMS 本身还提供缓存亲和性,这些工作都在同一个 CPU 上运行,因此可以获得重复使用其中缓存内容的优势。
但是,你可能会发现我们遇到了一个新问题,这也是基于多队列方法的基本问题:负载不平衡。假设我们有与上述相同的设置(四个工作、两个 CPU),但其中一个工作(比如 C)完成了。现在我们有以下调度队列:

如果我们在系统的每个队列上运行轮循策略,就会看到这样的调度表:

从图中可以看出,A 获得的 CPU 资源是 B 和 D 的两倍,这并不是我们想要的结果。更糟的是,假设 A 和 C 都完成了工作,系统中只剩下工作 B 和 D。调度队列将如下所示:

因此,CPU 0 将处于闲置状态!

那么,关键是怎么解决负载不均衡的问题呢?MQMS应如何处理负载不平衡问题,从而更好地实现预期调度目标?
对于这个问题,显而易见的答案就是移动作业,我们(再次)将这种技术称为迁移。通过将作业从一个 CPU 迁移到另一个 CPU,可以实现真正的负载平衡。让我们看几个例子来进一步说明。我们再一次遇到这样的情况:一个 CPU 空闲,另一个 CPU 有一些作业。
在这种情况下,所需的迁移很容易理解:操作系统只需将 B 或 D 中的一个迁移到 CPU 0。 这种单一作业迁移的结果是负载均衡,大家都很高兴。
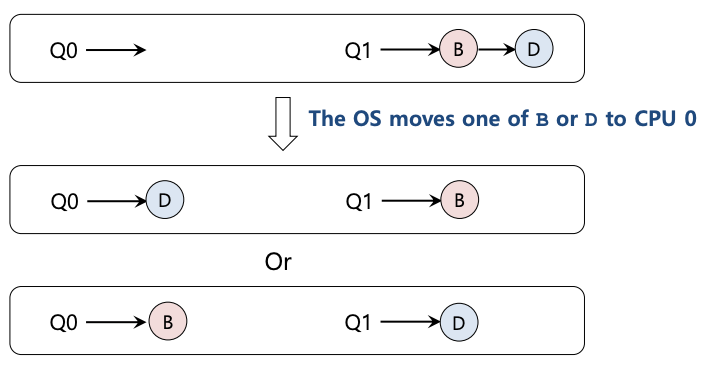
在我们之前的示例中出现了一个更棘手的情况,其中 A 单独留在 CPU 0 上,而 B 和 D 交替出现在 CPU 1 上:
在这种情况下,一次迁移并不能解决问题。在这种情况下该怎么办呢?答案是连续迁移一个或多个工作。一种可能的解决方案是不断切换工作,如下图所示。在图中,首先 A 单独运行在 CPU 0 上,B 和 D 交替运行在 CPU 1 上。几个时间片后,B 被转移到 CPU 0 上与 A 竞争,而 D 则在 CPU 1 上单独运行几个时间片。这样,负载就平衡了:
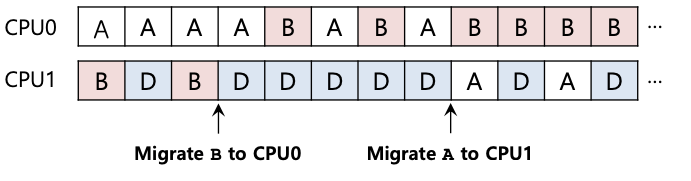
当然,还存在许多其他可能的迁移模式。但现在是棘手的部分:系统应该如何决定实施这样的迁移?
一种基本方法是使用一种称为工作窃取(work stealing)的技术。通过工作窃取方法,作业量较低的(源)队列偶尔会查看另一个(目标)队列,看看它有多满。如果目标队列(特别是)比源队列更满,则源队列将从目标“窃取”一个或多个作业以帮助平衡负载。
当然,这种方法自然会产生矛盾。如果过于频繁地查看其他队列,就会造成高开销和扩展困难,而实施多队列调度的目的就是为了解决这个问题!!另一方面,如果不经常查看其他队列,就有可能出现严重的负载不平衡。在系统策略设计中,找到合适的阈值仍然是一门黑科技。
6 Linux 多处理器调度器
有趣的是,Linux 社区在构建多处理器调度程序方面没有通用的解决方案。随着时间的推移,出现了三种不同的调度器:
O(1)调度器
- 基于优先级的调度程序
- 使用多队列(类似于MLFQ)
- 随着时间的推移改变流程的优先级
- 调度优先级高的进程
- 交互性是关注的重点
完全公平调度器(CFS)
使用多队列
确定性比例份额方法
基于阶梯截止日期(公平是重点)
红黑树可扩展性
BF调度器(BFS)
- 单队列调度方法
- 使用比例份额方法
- 基于最早符合条件的虚拟截止时间优先(EEVDF)
- 侧重于交互式(不能很好地扩展内核)。已被 MuQSS 取代,以解决这一问题
7 总结
我们已经看到了多种多处理器调度方法。单队列方法 (SQMS) 构建起来相当简单,并且可以很好地平衡负载,但本质上难以扩展到许多处理器和缓存亲和力。多队列方法(MQMS)可扩展性更好,并且可以很好地处理缓存亲和性,但存在负载不平衡的问题,并且更复杂。无论您采用哪种方法,都没有简单的答案:构建通用调度器仍然是一项艰巨的任务,因为小的代码更改可能会导致大的行为差异。
相关内容
 支付宝
支付宝 微信
微信