typeRaftstruct{musync.RWMutex// Lock to protect shared access to this peer's state, to use RWLock for better performance
peers[]*labrpc.ClientEnd// RPC end points of all peers
persister*Persister// Object to hold this peer's persisted state
meint// this peer's index into peers[]
deadint32// set by Kill()
// Persistent state on all servers(Updated on stable storage before responding to RPCs)
currentTermint// latest term server has seen(initialized to 0 on first boot, increases monotonically)
votedForint// candidateId that received vote in current term(or null if none)
logs[]LogEntry// log entries; each entry contains command for state machine, and term when entry was received by leader(first index is 1)
// Volatile state on all servers
commitIndexint// index of highest log entry known to be committed(initialized to 0, increases monotonically)
lastAppliedint// index of highest log entry applied to state machine(initialized to 0, increases monotonically)
// Volatile state on leaders(Reinitialized after election)
nextIndex[]int// for each server, index of the next log entry to send to that server(initialized to leader last log index + 1)
matchIndex[]int// for each server, index of highest log entry known to be replicated on server(initialized to 0, increases monotonically)
// other properties
stateNodeState// current state of the server
electionTimer*time.Timer// timer for election timeout
heartbeatTimer*time.Timer// timer for heartbeat
applyChchanApplyMsg// channel to send apply message to service
applyCond*sync.Cond// condition variable for apply goroutine
replicatorCond[]*sync.Cond// condition variable for replicator goroutine
}funcMake(peers[]*labrpc.ClientEnd,meint,persister*Persister,applyChchanApplyMsg)*Raft{rf:=&Raft{mu:sync.RWMutex{},peers:peers,persister:persister,me:me,dead:0,currentTerm:0,votedFor:-1,logs:make([]LogEntry,1),// dummy entry at index 0
commitIndex:0,lastApplied:0,nextIndex:make([]int,len(peers)),matchIndex:make([]int,len(peers)),state:Follower,electionTimer:time.NewTimer(RandomElectionTimeout()),heartbeatTimer:time.NewTimer(StableHeartbeatTimeout()),applyCh:applyCh,replicatorCond:make([]*sync.Cond,len(peers)),}// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())// should use mu to protect applyCond, avoid other goroutine to change the critical section
rf.applyCond=sync.NewCond(&rf.mu)// initialize nextIndex and matchIndex, and start replicator goroutine
forpeer:=rangepeers{rf.matchIndex[peer],rf.nextIndex[peer]=0,rf.getLastLog().Index+1ifpeer!=rf.me{rf.replicatorCond[peer]=sync.NewCond(&sync.Mutex{})// start replicator goroutine to send log entries to peer
gorf.replicator(peer)}}// start ticker goroutine to start elections
gorf.ticker()// start apply goroutine to apply log entries to state machine
gorf.applier()returnrf}
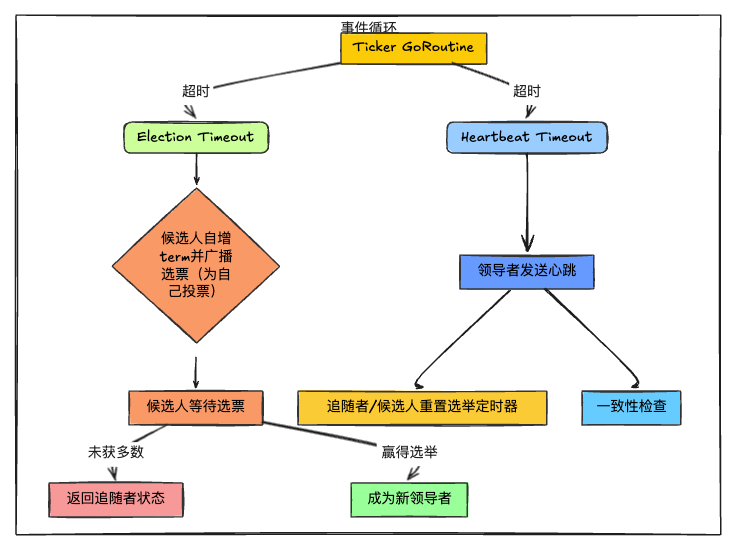
func(rf*Raft)ticker(){forrf.killed()==false{select{case<-rf.electionTimer.C:rf.mu.Lock()rf.ChangeState(Candidate)rf.currentTerm+=1// start election
rf.StartElection()rf.electionTimer.Reset(RandomElectionTimeout())// reset election timer in case of split vote
rf.mu.Unlock()case<-rf.heartbeatTimer.C:rf.mu.Lock()ifrf.state==Leader{// should send heartbeat
rf.BroadcastHeartbeat(true)rf.heartbeatTimer.Reset(StableHeartbeatTimeout())}rf.mu.Unlock()}}}
func(rf*Raft)StartElection(){rf.votedFor=rf.meargs:=rf.genRequestVoteArgs()grantedVotes:=1forpeer:=rangerf.peers{ifpeer==rf.me{continue}gofunc(peerint){reply:=new(RequestVoteReply)ifrf.sendRequestVote(peer,args,reply){rf.mu.Lock()deferrf.mu.Unlock()ifargs.Term==rf.currentTerm&&rf.state==Candidate{ifreply.VoteGranted{grantedVotes+=1// check over half of the votes
ifgrantedVotes>len(rf.peers)/2{rf.ChangeState(Leader)rf.BroadcastHeartbeat(true)}}elseifreply.Term>rf.currentTerm{rf.ChangeState(Follower)rf.currentTerm,rf.votedFor=reply.Term,-1}}}}(peer)}}
func(rf*Raft)RequestVote(args*RequestVoteArgs,reply*RequestVoteReply){rf.mu.Lock()deferrf.mu.Unlock()deferDPrintf("{Node %v}'s state is {state %v, term %v}} after processing RequestVote, RequestVoteArgs %v and RequestVoteReply %v ",rf.me,rf.state,rf.currentTerm,args,reply)// Reply false if term < currentTerm(§5.1)
// if the term is same as currentTerm, and the votedFor is not null and not the candidateId, then reject the vote(§5.2)
ifargs.Term<rf.currentTerm||(args.Term==rf.currentTerm&&rf.votedFor!=-1&&rf.votedFor!=args.CandidateId){reply.Term,reply.VoteGranted=rf.currentTerm,falsereturn}ifargs.Term>rf.currentTerm{rf.ChangeState(Follower)rf.currentTerm,rf.votedFor=args.Term,-1}// if candidate's log is not up-to-date, reject the vote(§5.4)
if!rf.isLogUpToDate(args.LastLogIndex,args.LastLogTerm){reply.Term,reply.VoteGranted=rf.currentTerm,falsereturn}rf.votedFor=args.CandidateIdrf.electionTimer.Reset(RandomElectionTimeout())reply.Term,reply.VoteGranted=rf.currentTerm,true}
func(rf*Raft)AppendEntries(args*AppendEntriesArgs,reply*AppendEntriesReply){// Your code here (3A, 3B).
rf.mu.Lock()deferrf.mu.Unlock()deferDPrintf("{Node %v}'s state is {state %v, term %v}} after processing AppendEntries, AppendEntriesArgs %v and AppendEntriesReply %v ",rf.me,rf.state,rf.currentTerm,args,reply)// Reply false if term < currentTerm(§5.1)
ifargs.Term<rf.currentTerm{reply.Term,reply.Success=rf.currentTerm,falsereturn}// indicate the peer is the leader
ifargs.Term>rf.currentTerm{rf.currentTerm,rf.votedFor=args.Term,-1}rf.ChangeState(Follower)rf.electionTimer.Reset(RandomElectionTimeout())// Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm(§5.3)
ifargs.PrevLogIndex<rf.getFirstLog().Index{reply.Term,reply.Success=rf.currentTerm,falsereturn}// check the log is matched, if not, return the conflict index and term
// if an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it(§5.3)
if!rf.isLogMatched(args.PrevLogIndex,args.PrevLogTerm){reply.Term,reply.Success=rf.currentTerm,falselastLogIndex:=rf.getLastLog().Index// find the first index of the conflicting term
iflastLogIndex<args.PrevLogIndex{// the last log index is smaller than the prevLogIndex, then the conflict index is the last log index
reply.ConflictIndex,reply.ConflictTerm=lastLogIndex+1,-1}else{firstLogIndex:=rf.getFirstLog().Index// find the first index of the conflicting term
index:=args.PrevLogIndexforindex>=firstLogIndex&&rf.logs[index-firstLogIndex].Term==args.PrevLogTerm{index--}reply.ConflictIndex,reply.ConflictTerm=index+1,args.PrevLogTerm}return}// append any new entries not already in the log
firstLogIndex:=rf.getFirstLog().Indexforindex,entry:=rangeargs.Entries{// find the junction of the existing log and the appended log.
ifentry.Index-firstLogIndex>=len(rf.logs)||rf.logs[entry.Index-firstLogIndex].Term!=entry.Term{rf.logs=append(rf.logs[:entry.Index-firstLogIndex],args.Entries[index:]...)break}}// If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry) (paper)
newCommitIndex:=Min(args.LeaderCommit,rf.getLastLog().Index)ifnewCommitIndex>rf.commitIndex{rf.commitIndex=newCommitIndexrf.applyCond.Signal()}reply.Term,reply.Success=rf.currentTerm,true}
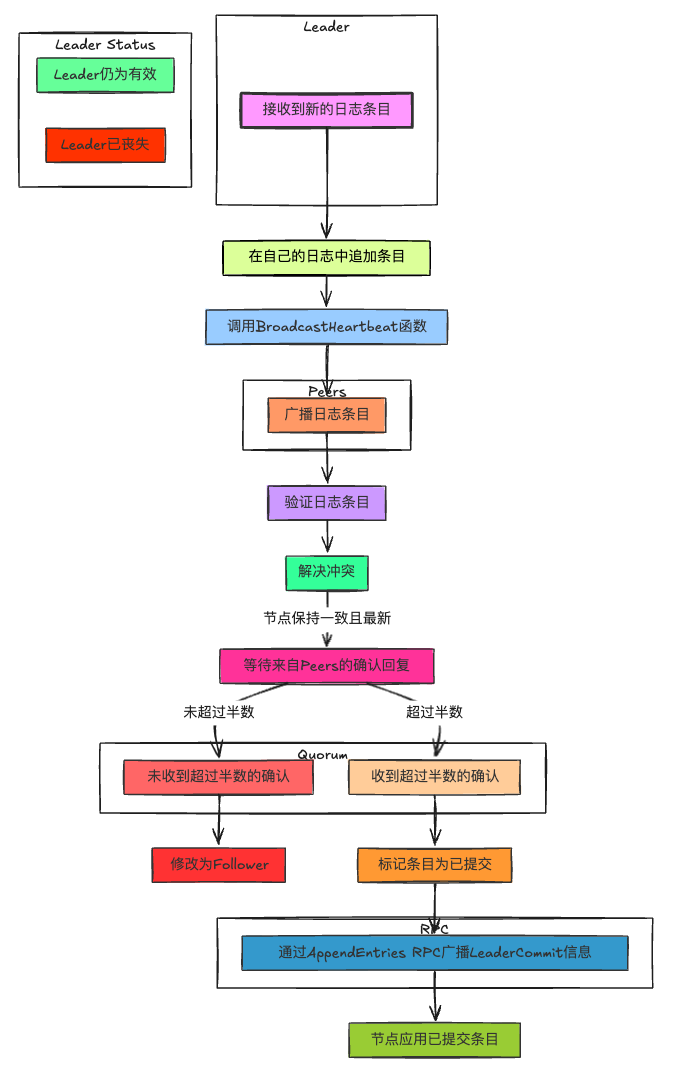
func(rf*Raft)replicateOnceRound(peerint){rf.mu.RLock()ifrf.state!=Leader{rf.mu.RUnlock()return}prevLogIndex:=rf.nextIndex[peer]-1args:=rf.genAppendEntriesArgs(prevLogIndex)rf.mu.RUnlock()reply:=new(AppendEntriesReply)ifrf.sendAppendEntries(peer,args,reply){rf.mu.Lock()ifargs.Term==rf.currentTerm&&rf.state==Leader{if!reply.Success{ifreply.Term>rf.currentTerm{// indicate current server is not the leader
rf.ChangeState(Follower)rf.currentTerm,rf.votedFor=reply.Term,-1}elseifreply.Term==rf.currentTerm{// decrease nextIndex and retry
rf.nextIndex[peer]=reply.ConflictIndexifreply.ConflictTerm!=-1{firstLogIndex:=rf.getFirstLog().Indexforindex:=args.PrevLogIndex-1;index>=firstLogIndex;index--{ifrf.logs[index-firstLogIndex].Term==reply.ConflictTerm{rf.nextIndex[peer]=indexbreak}}}}}else{rf.matchIndex[peer]=args.PrevLogIndex+len(args.Entries)rf.nextIndex[peer]=rf.matchIndex[peer]+1// advance commitIndex if possible
rf.advanceCommitIndexForLeader()}}rf.mu.Unlock()}}
Leader应用已提交log的advanceCommitIndexForLeader函数实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
func(rf*Raft)advanceCommitIndexForLeader(){n:=len(rf.matchIndex)sortMatchIndex:=make([]int,n)copy(sortMatchIndex,rf.matchIndex)sort.Ints(sortMatchIndex)// get the index of the log entry with the highest index that is known to be replicated on a majority of servers
newCommitIndex:=sortMatchIndex[n-(n/2+1)]ifnewCommitIndex>rf.commitIndex{ifrf.isLogMatched(newCommitIndex,rf.currentTerm){rf.commitIndex=newCommitIndexrf.applyCond.Signal()}}}
func(rf*Raft)applier(){forrf.killed()==false{rf.mu.Lock()// check the commitIndex is advanced
forrf.commitIndex<=rf.lastApplied{// need to wait for the commitIndex to be advanced
rf.applyCond.Wait()}// apply log entries to state machine
firstLogIndex,commitIndex,lastApplied:=rf.getFirstLog().Index,rf.commitIndex,rf.lastAppliedentries:=make([]LogEntry,commitIndex-lastApplied)copy(entries,rf.logs[lastApplied-firstLogIndex+1:commitIndex-firstLogIndex+1])rf.mu.Unlock()// send the apply message to applyCh for service/State Machine Replica
for_,entry:=rangeentries{rf.applyCh<-ApplyMsg{CommandValid:true,Command:entry.Command,CommandIndex:entry.Index,}}rf.mu.Lock()// use commitIndex rather than rf.commitIndex because rf.commitIndex may change during the Unlock() and Lock()
rf.lastApplied=commitIndexrf.mu.Unlock()}}
func(rf*Raft)readPersist(data[]byte){ifdata==nil||len(data)<1{// bootstrap without any state?
return}r:=bytes.NewBuffer(data)d:=labgob.NewDecoder(r)varcurrentTerm,votedForintvarlogs[]LogEntryifd.Decode(¤tTerm)!=nil||d.Decode(&votedFor)!=nil||d.Decode(&logs)!=nil{DPrintf("{Node %v} fails to decode persisted state",rf.me)}rf.currentTerm,rf.votedFor,rf.logs=currentTerm,votedFor,logsrf.lastApplied,rf.commitIndex=rf.getFirstLog().Index,rf.getFirstLog().Index}
func(rf*Raft)InstallSnapshot(args*InstallSnapshotArgs,reply*InstallSnapshotReply){rf.mu.Lock()deferrf.mu.Unlock()reply.Term=rf.currentTerm// reply immediately if term < currentTerm
ifargs.Term<rf.currentTerm{return}ifargs.Term>rf.currentTerm{rf.currentTerm,rf.votedFor=args.Term,-1rf.persist()}rf.ChangeState(Follower)rf.electionTimer.Reset(RandomElectionTimeout())// check the snapshot is more up-to-date than the current log
ifargs.LastIncludedIndex<=rf.commitIndex{return}gofunc(){rf.applyCh<-ApplyMsg{SnapshotValid:true,Snapshot:args.Data,SnapshotTerm:args.LastIncludedTerm,SnapshotIndex:args.LastIncludedIndex,}}()}
Snapshot函数实现如下,它接收客户端创建的快照。
1
2
3
4
5
6
7
8
9
10
11
12
13
func(rf*Raft)Snapshot(indexint,snapshot[]byte){rf.mu.Lock()deferrf.mu.Unlock()snapshotIndex:=rf.getFirstLog().Indexifindex<=snapshotIndex||index>rf.getLastLog().Index{DPrintf("{Node %v} rejects replacing log with snapshotIndex %v as current snapshotIndex %v is larger in term %v",rf.me,index,snapshotIndex,rf.currentTerm)return}// remove log entries up to index
rf.logs=rf.logs[index-snapshotIndex:]rf.logs[0].Command=nilrf.persister.SaveStateAndSnapshot(rf.encodeState(),snapshot)}
func(rf*Raft)CondInstallSnapshot(lastIncludedTermint,lastIncludedIndexint,snapshot[]byte)bool{rf.mu.Lock()deferrf.mu.Unlock()// outdated snapshot
iflastIncludedIndex<=rf.commitIndex{returnfalse}// need dummy entry at index 0
iflastIncludedIndex>rf.getLastLog().Index{rf.logs=make([]LogEntry,1)}else{rf.logs=rf.logs[lastIncludedIndex-rf.getFirstLog().Index:]rf.logs[0].Command=nil}rf.logs[0].Term,rf.logs[0].Index=lastIncludedTerm,lastIncludedIndexrf.commitIndex,rf.lastApplied=lastIncludedIndex,lastIncludedIndexrf.persister.SaveStateAndSnapshot(rf.encodeState(),snapshot)}
#!/bin/bash
# check the number of argumentsif["$#" -ne 2];thenecho"Usage: $0 <test_type> <iterations>"echo"test_type must be one of 3A, 3B, 3C, 3D"exit1fitest_type=$1iterations=$2# check the test_typeif[["$test_type" !="3A"&&"$test_type" !="3B"&&"$test_type" !="3C"&&"$test_type" !="3D"]];thenecho"Invalid test_type: $test_type"echo"test_type must be one of 3A, 3B, 3C, 3D"exit1fi# check the iterations is a positive integerif ! [["$iterations"=~ ^[0-9]+$ ]];thenecho"Invalid iterations: $iterations"echo"iterations must be a positive integer"exit1fiecho"go test -run $test_type"for((i=1; i<=iterations; i++))doecho"Running test iteration $i"output=$(go test -run $test_type 2>&1)#>&1 redirects stderr to stdoutif[[$? -ne 0]];thenecho"Error in iteration $i:"echo"$output"fidone




 支付宝
支付宝 微信
微信