地址转换
虚拟化内存使用的通用技术被称为基于硬件的地址转换,或者简称为地址转换,您可以将其视为对有限直接执行的通用方法的补充。通过地址转换,硬件可以转换每个内存访问(例如,指令提取、加载或存储),将指令提供的虚拟地址更改为所需信息实际所在的物理地址。因此,对于每个存储器引用,硬件都会执行地址转换,以将应用程序存储器引用重定向到它们在存储器中的实际位置。当然,硬件本身无法虚拟化内存,因为它只是提供了有效地虚拟化内存的低级机制。操作系统必须在关键点参与设置硬件,以便进行正确的转换;因此,它必须管理内存,跟踪哪些位置是空闲的,哪些位置正在使用,并明智地进行干预以保持对内存使用方式的控制。
所有这些工作的目标再次是创造一个美丽的幻觉:程序拥有自己的私有内存,其中驻留着自己的代码和数据。虚拟现实的背后隐藏着丑陋的物理事实:当 CPU(或多个 CPU)在运行一个程序和下一个程序之间切换时,许多程序实际上同时共享内存。通过虚拟化,操作系统(在硬件的帮助下)将丑陋的机器现实转变为有用、强大且易于使用的抽象。
1 假设(第一次尝试)
- 用户地址空间在内存中是连续的
- 用户地址空间小于物理内存(最大64KB)
- 每个地址空间具有相同的大小(最大16KB)
2 例子
我们看一个简单的例子。假设有一个进程,其地址空间如下图所示。
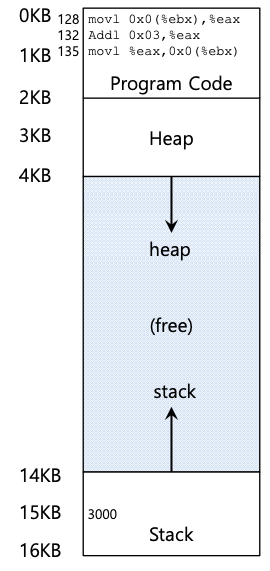
我们要研究的是一个简短的代码序列:从内存中加载一个值,将其增加 3,然后将该值存储回内存中。
| |
编译器将这行代码转换为汇编语言,可能看起来像这样(在 x86 汇编语言中)。在 Linux 上使用 objdump 或在 Mac 上使用 otool 来反汇编它:
| |
这段代码相对简单;它假定 x 的地址已放入寄存器 ebx 中,然后使用 movl 指令(用于“长字”移动)将该地址处的值加载到通用寄存器 eax 中。下一条指令将 eax 加 3,最后一条指令将 eax 中的值存储回内存中的同一位置。
在上图中,观察代码和数据在进程地址空间中的布局方式;三指令代码序列位于地址 128(在靠近顶部的代码段中),变量 x 的值位于地址 15 KB(在靠近底部的堆栈中)。图中,x的初始值为3000,如其在堆栈中的位置所示。当这些指令运行时,从进程的角度来看,会发生以下内存访问。
- 取地址 128 的指令
- 执行该指令(从地址 15 KB 加载)
- 取地址 132 的指令 - 执行该指令(无内存引用)
- 取地址 135 的指令
- 执行该指令(存储到地址 15 KB)
从程序的角度来看,它的地址空间从地址0开始,最大增长到16KB;它生成的所有内存引用都应该在这些范围内。然而,为了虚拟化内存,操作系统希望将进程放置在物理内存中的其他位置,而不一定是地址0。因此,我们遇到了问题:如何以对进程透明的方式在内存中重新定位该进程?当实际上地址空间位于其他物理地址时,我们如何提供从 0 开始的虚拟地址空间的假象?
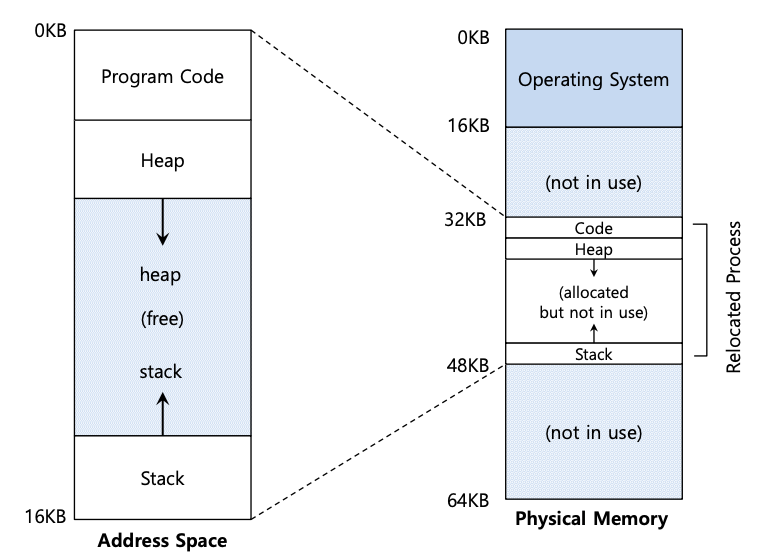
下图展示了进程的地址空间放入内存后物理内存可能是什么样子。在图中,您可以看到操作系统为自己使用物理内存的第一个插槽,并且它已将上例中的进程重新定位到从物理内存地址 32 KB 开始的插槽中。另外两个插槽是空闲的(16 KB-32 KB 和 48 KB-64 KB)。
3 动态(基于硬件)重定位
为了对基于硬件的地址转换有一定的了解,我们首先讨论它的第一个版本。 1950 年代末的第一台分时机中引入了一个简单的概念,称为基数和边界;该技术也称为动态重定位;我们将交替使用这两个术语。
具体来说,每个 CPU 中我们需要两个硬件寄存器:一个称为基址寄存器,另一个称为边界寄存器(有时称为限制寄存器)。这个基址和边界对将允许我们将地址空间放置在物理内存中的任何位置,并同时确保进程只能访问自己的地址空间。
在此设置中,每个程序都被编写和编译,就好像它被加载到地址零一样。但是,当程序开始运行时,操作系统会决定应将其加载到物理内存中的何处,并将基址寄存器设置为该值。
在上面的示例中,操作系统决定在物理地址 32 KB 处加载进程,从而将基址寄存器设置为该值,如下图所示。
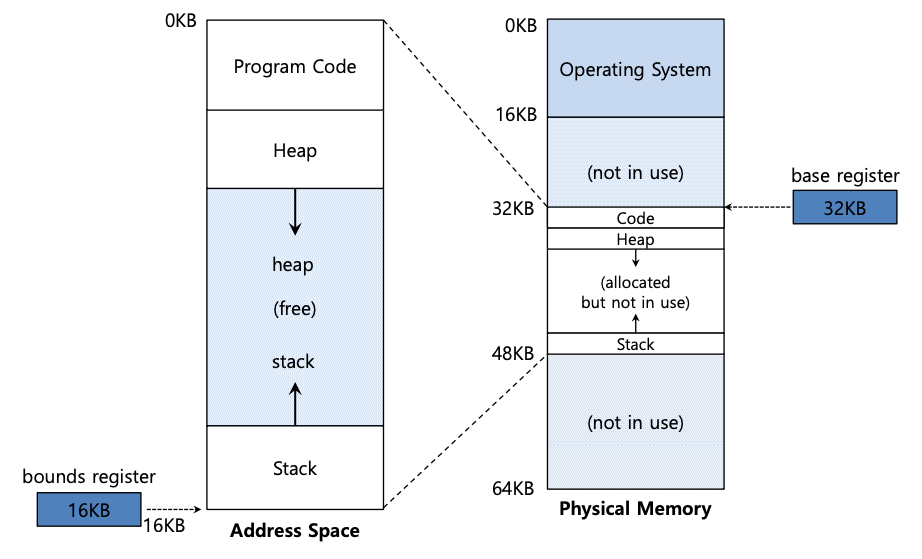
当进程运行时,有趣的事情开始发生。现在,当进程生成任何内存引用时,处理器会按以下方式对其进行转换:
| |
进程生成的每个内存引用都是一个虚拟地址;硬件依次将基址寄存器的内容添加到该地址,结果是内存系统的物理地址。
为了更好地理解这一点,让我们追踪一下执行单个指令时会发生什么。具体来说,让我们看一下前面序列中的一条指令:
| |
程序计数器 (PC) 设置为 128;当硬件需要取该指令时,首先将该值与基址寄存器值32 KB(32768)相加,得到物理地址32896;然后硬件从该物理地址获取指令。
接下来,处理器开始执行指令。在某个时刻,进程会从虚拟地址 15 KB 发出加载,处理器将其获取并再次添加到基址寄存器 (32 KB),从而获得 47 KB 的最终物理地址,从而获得所需的内容。
将虚拟地址转换为物理地址正是我们所说的地址转换技术;也就是说,硬件获取进程认为它正在引用的虚拟地址,并将其转换为数据实际驻留的物理地址。因为这种地址重定位发生在运行时,并且即使在进程开始运行后我们也可以移动地址空间,所以该技术通常称为动态重定位。
现在您可能会问:边界(限制)寄存器发生了什么,起到了什么作用?毕竟,这不是基数和边界方法吗?它的确是。正如您可能已经猜到的,边界寄存器是为了帮助保护。具体来说,处理器会首先检查内存引用是否在范围内,以确保它是合法的;在上面的简单示例中,边界寄存器将始终设置为 16 KB。如果进程生成的虚拟地址大于边界,或者为负数,CPU 将引发异常,并且该进程可能会被终止。因此,边界的目的是确保进程生成的所有地址都是合法的并且在进程的“边界”内。
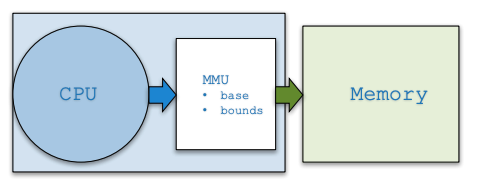
我们应该注意,基址寄存器和边界寄存器是保存在芯片上的硬件结构(每个 CPU 一对)。有时人们将处理器中帮助进行地址转换的部分称为内存管理单元(MMU);随着我们开发更复杂的内存管理技术,我们将为 MMU 添加更多电路。如下图所示。
为了更详细地理解通过基址和边界进行的地址转换,让我们来看一个例子。想象一下,一个地址空间大小为 4 KB的进程被加载到物理地址 16 KB。下面是一些地址转换的结果:
| Virtual Address | Physical Address |
|---|---|
| 0 | 16 KB |
| 1 KB | 17 KB |
| 3000 | 19384 |
| 4400 | Fault (Out of Bounds) |
从示例中可以看出,只需将基地址与虚拟地址相加(可以正确地将其视为地址空间的偏移量),就可以轻松得到物理地址。只有当虚拟地址 “过大 “或为负数时,结果才会是一个错误,从而引发异常。
4 内存虚拟化的操作系统问题
正如硬件提供了支持动态重定位的新功能一样,操作系统现在也有必须处理的新问题;硬件支持和操作系统管理的结合导致了简单虚拟内存的实现。具体来说,有几个关键时刻,操作系统必须参与其中,以实现我们的虚拟内存的基址和边界版本。
首先,操作系统必须在创建进程时采取行动,为其在内存中的地址空间找到空间。幸运的是,考虑到我们假设每个地址空间(a)小于物理内存的大小以及(b)相同的大小,这对于操作系统来说非常容易;它可以简单地将物理内存视为一组插槽,并跟踪每个插槽是否空闲或正在使用。创建新进程时,操作系统必须搜索数据结构(通常称为空闲列表)来为新地址空间找到空间,然后将其标记为已使用。对于可变大小的地址空间,情况会更加复杂。
让我们看一个例子。如下图所示,您可以看到操作系统为自己使用物理内存的第一个插槽,并且它已将上面示例中的进程重新定位到从物理内存地址 32 KB 开始的插槽中。另外两个插槽是空闲的(16 KB-32 KB 和 48 KB-64 KB);因此,空闲列表应该由这两个条目组成。
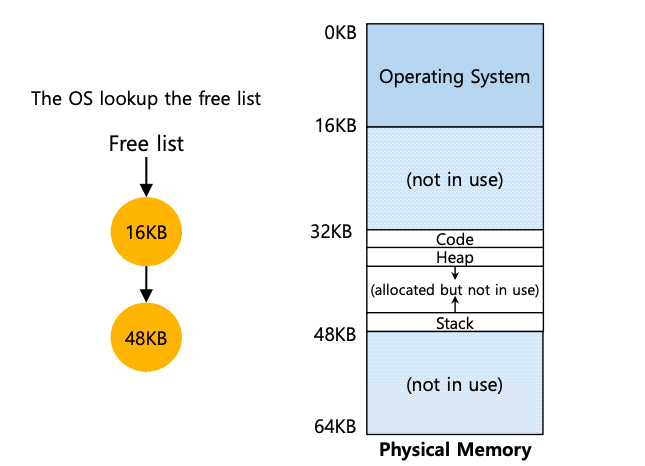
第二,当进程终止时(即,当它正常退出或由于行为不当而被强制终止时),操作系统必须做一些工作,回收其所有内存以供其他进程或操作系统使用。进程终止后,操作系统会将其内存放回到空闲列表中,并根据需要清理任何关联的数据结构,如下图所示。
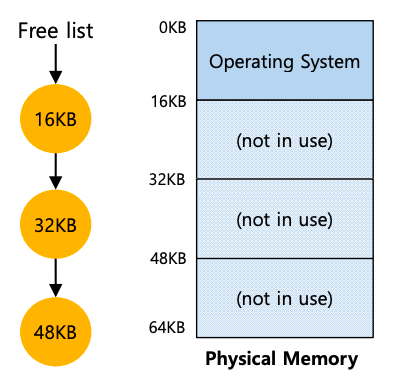
第三,当发生上下文切换时,操作系统还必须执行一些额外的步骤。毕竟,每个 CPU 上只有一对基址和边界寄存器,并且每个正在运行的程序的值都不同,因为每个程序都加载到内存中不同的物理地址。因此,操作系统在进程之间切换时必须保存和恢复基址和边界对。
具体来说,当操作系统决定停止运行某个进程时,它必须将基址寄存器和边界寄存器的值保存到内存中的某些每个进程的结构中,例如进程结构或进程控制块 (PCB)。同样,当操作系统恢复正在运行的进程(或第一次运行它)时,它必须将 CPU 上的基数和边界值设置为该进程的正确值,如下图所示。
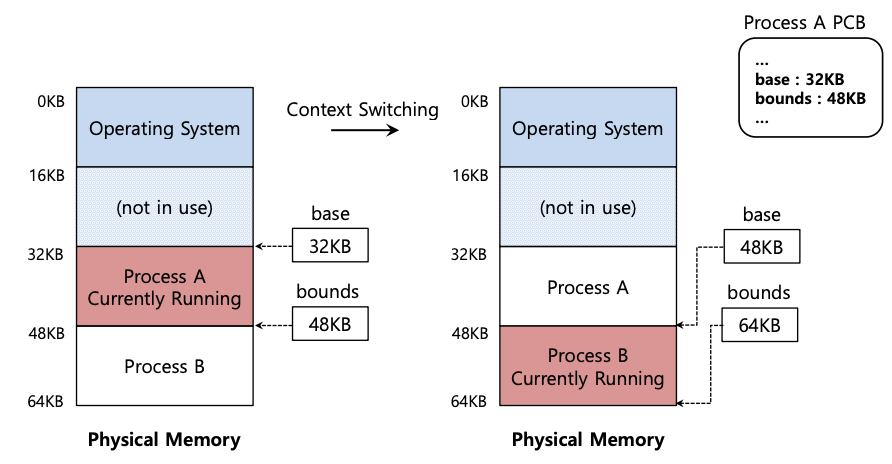
我们应该注意到,当进程停止(即不运行)时,操作系统可以很容易地将地址空间从内存中的一个位置移动到另一个位置。要移动进程的地址空间,操作系统首先会对进程取消调度;然后,操作系统会将地址空间从当前位置复制到新位置;最后,操作系统会更新(进程结构中的)保存基址寄存器,使其指向新位置。当进程恢复时,它的(新)基址寄存器会被恢复,然后它又开始运行,全然不顾它的指令和数据现在在内存中一个全新的位置。
第四,如上所述,操作系统必须提供异常处理程序或调用函数;操作系统在启动时(通过特权指令)安装这些处理程序。例如,如果一个进程试图访问超出其边界的内存,CPU 就会引发异常;操作系统必须做好准备,在出现这种异常时采取行动。操作系统的通常反应是敌意:它可能会终止违规进程。操作系统应高度保护它所运行的机器,因此它不会善待试图访问内存或执行不该执行指令的进程。
下表以时间轴的形式展示了硬件与操作系统之间的交互。表中显示了操作系统在启动时为准备使用机器所做的工作,以及进程(进程 A)开始运行时发生的情况;请注意其内存转换是如何在没有操作系统干预的情况下由硬件处理的。此时,操作系统必须介入,终止进程并清理 B 的内存,将其从进程表中删除。从表中可以看出,我们仍然遵循有限直接执行的基本方法。在大多数情况下,操作系统只需适当设置硬件,让进程直接在 CPU 上运行;只有当进程出现异常时,操作系统才会介入。
| OS @ boot (kernel mode) | Hardware | Program (user mode) |
|---|---|---|
| 初始化中断表 | 记住系统调用处理程序、定时器处理程序 、非法内存访问处理程序、非法指令处理程序……的地址 | - |
| 启动中断定时器 | 启动计时器;X 毫秒后中断 | - |
| 初始化进程表;初始化空闲列表 | - | - |
| OS @ run (kernel mode) | Hardware | Program (user mode) |
| 启动进程 A: 分配进程表中的条目;为进程分配内存;设置基准/边界寄存器 ;从中断返回(进入 A) | - | - |
| 恢复 A 的寄存器;移动到用户模式;跳转到 A 的(初始)PC | 进程 A 运行;取指令 | |
| 转换虚拟地址并执行提取 | 执行指令 | |
| 如果是显式加载/存储:确保地址在边界内;转换虚拟地址并执行加载/存储 | ||
| 定时器中断转入内核模式;跳转到中断处理程序 | ||
| 处理中断; 调用 switch() 例程 ;将 regs(A) 保存到 proc-struct(A)(包括基址/边界) ;从 proc-struct(B)(包括基址/边界)恢复 regs(B) ;从中断返回 (进入B) | ||
| 恢复B的寄存器;转移到用户模式; 跳转到B的PC | ||
| 进程B运行;执行错误加载 | ||
| 加载越界;转入内核模式,跳转到中断处理程序 | ||
| 处理中断;决定终止进程 B;释放 B 的内存;释放 B 在进程表中的条目 |
5 总结
在本章中,我们用虚拟内存中使用的一种特定机制(即地址转换)扩展了有限直接执行的概念。通过地址转换,操作系统可以控制进程的每次内存访问,确保访问不超出地址空间的范围。硬件支持是这项技术高效的关键,它能为每次访问快速执行转换,将虚拟地址(进程对内存的看法)转换为物理地址(实际看法)。所有这些都是以对被重定位的进程透明的方式进行的,进程根本不知道其内存引用正在被转换,这就造成了一种奇妙的错觉。
我们还看到了一种特殊形式的虚拟化,即基址边界虚拟化或动态重定位。基址边界虚拟化相当高效,因为只需要多一点硬件逻辑,就能在虚拟地址中添加一个基址寄存器,并检查进程生成的地址是否在边界内。基址边界虚拟化还能提供保护;操作系统和硬件相结合,确保任何进程都无法在自身地址空间之外生成内存引用。保护无疑是操作系统最重要的目标之一;如果没有保护,操作系统就无法控制机器(如果进程可以随意覆盖内存,它们就能轻易做出一些令人讨厌的事情,比如覆盖中断表并接管系统)。
不过,这种简单的动态重定位技术确实存在效率低下的问题。例如,如上图所示,重定位后的进程使用的物理内存从 32 KB 增加到 48 KB,但由于进程堆栈和堆并不太大,两者之间的所有空间都被浪费掉了。这种浪费通常被称为内部碎片,因为分配单元内部的空间没有被全部使用(即被碎片化),从而造成浪费。在我们目前的方法中,虽然可能有足够的物理内存来容纳更多进程,但我们目前只能将地址空间放置在固定大小的插槽中,因此可能会出现内部碎片。因此,我们需要更复杂的机制来更好地利用物理内存,避免内部碎片。
相关内容
 支付宝
支付宝 微信
微信