段
1 分段:广义基数/边界
到目前为止,我们已经将每个进程的整个地址空间放入内存中。通过基址寄存器和边界寄存器,操作系统可以轻松地将进程重新定位到物理内存的不同部分。然而,您可能已经注意到我们的这些地址空间有一些有趣的地方:在栈和堆之间的中间有一大块“空闲”空间,如下图所示。
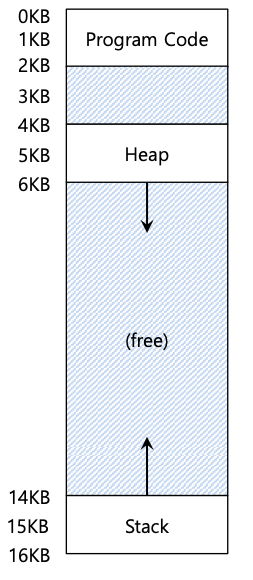
虽然栈和堆之间的空间没有被进程使用,但当我们将整个地址空间重新定位到物理内存中的某个位置时,它仍然占用物理内存;因此,使用基址和边界寄存器对来虚拟化内存的简单方法是浪费的。当整个地址空间无法放入内存时,它也会使程序的运行变得非常困难;因此,基数和边界并不像我们希望的那样灵活。因此:关键:如何支持大地址空间 我们如何支持大地址空间以及栈和堆之间(可能)有大量可用空间?
为了解决这个问题,一个想法应运而生,它就是分段。这是一个相当古老的想法,至少可以追溯到 1960 年代初。这个想法很简单:与其在我们的 MMU 中只有一个基址和边界对,为什么不在地址空间的每个逻辑段都有一个基址和边界对呢?段只是特定长度的地址空间的连续部分,在我们的规范地址空间中,我们有三个逻辑上不同的段:代码、栈和堆。分段允许操作系统做的是将每个段放置在物理内存的不同部分,从而避免用未使用的虚拟地址空间填充物理内存。
让我们看一下例子,假设我们要将下图中的地址空间放入物理内存中。由于每个段都有一个基址和边界对,我们可以将每个段独立地放置在物理内存中。您可以看到 64KB 物理内存,其中包含这三个段(还有 16KB 为操作系统保留)
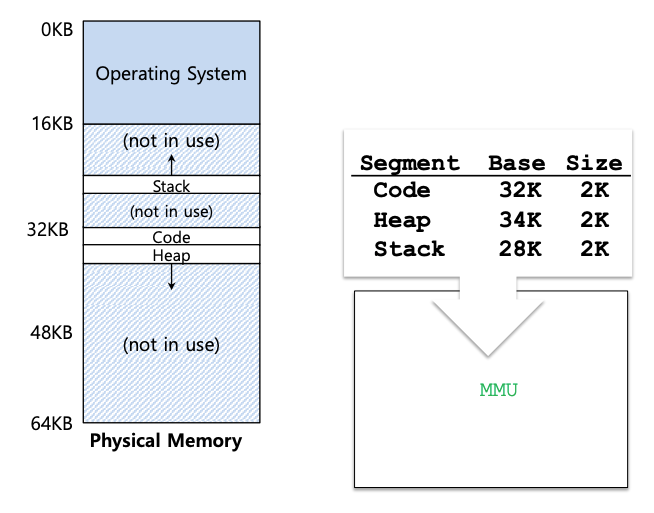
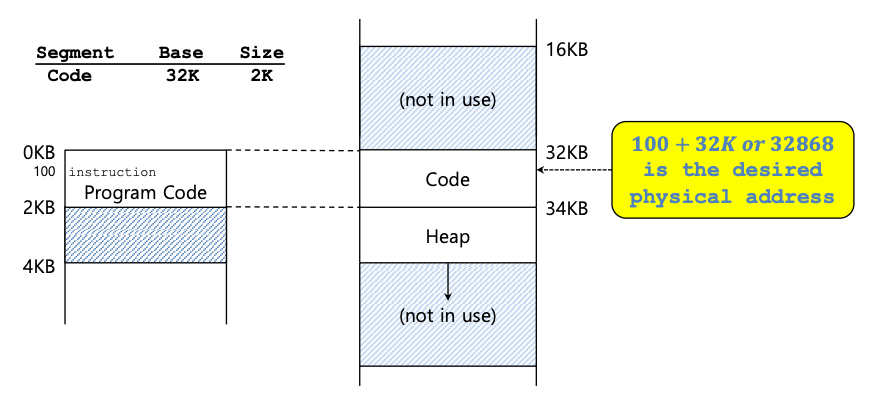
从图中可以看到,代码段放置在物理地址32KB,大小为2KB,堆段放置在34KB,大小也为2KB。假设对虚拟地址 100(位于代码段中,代码段从地址空间中的虚拟地址0开始。)进行了引用。当发生引用时(例如,在指令获取时),硬件会将基址值添加到该段的偏移量(本例中为 100),以达到所需的物理地址:100 + 32KB,或 32868。然后检查该地址是否在范围内(100小于2KB),发现它在范围内,然后发出对物理内存地址32868的引用。
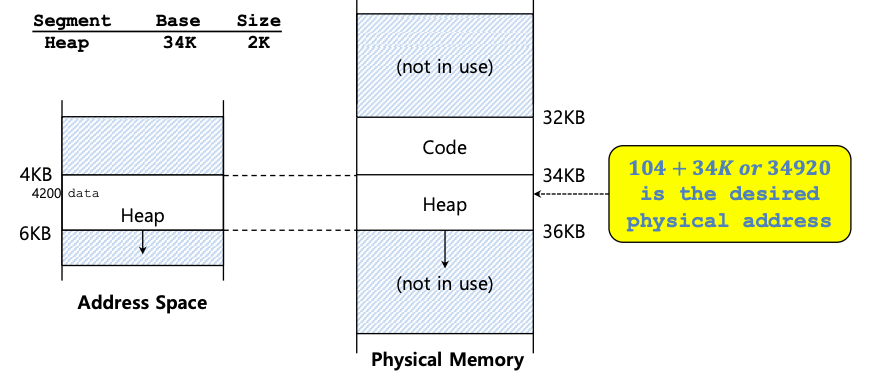
现在让我们看一下堆中的一个地址,虚拟地址 4200,如下图所示。如果我们只是将虚拟地址 4200 添加到堆基址 (34KB),我们会得到物理地址 39016,这不是正确的物理地址。我们首先需要做的是将偏移量提取到堆中,即地址引用了该段中的哪个字节。因为堆从虚拟地址 4KB (4096) 开始,所以 4200 的偏移量实际上是 4200 减去 4096,即 104。然后我们将这个偏移量 (104) 添加到基址寄存器物理地址 (34K) 以获得所需的结果:34920。
如果我们尝试引用非法地址,例如超出堆末尾的7KB,如下图所示,该怎么办?您可以想象会发生什么:硬件检测到地址越界,进入操作系统中断,可能导致违规进程终止。现在您知道了所有 C 程序员都害怕的著名术语的由来:分段违规或分段错误。
“分段错误”或“违规”是由分段机器上对非法地址的内存访问引起的。有趣的是,这个术语仍然存在,即使在根本不支持分段的机器上也是如此。或者,如果你无法弄清楚为什么你的代码总是出错,那就不那么幽默了。

2 引用段
硬件在转换期间使用段寄存器。它如何知道段中的偏移量以及地址引用哪个段?
一种常见的方法(有时称为显式方法)是根据虚拟地址的前几位将地址空间分成多个段;该技术用于 VAX/VMS 系统。在上面的例子中,我们有三个部分;因此我们需要两个位来完成我们的任务。如果我们使用 14 位虚拟地址的前两位来选择段,我们的虚拟地址如下所示:

在我们的示例中,如果前两位是 00,则硬件知道虚拟地址位于代码段中,因此使用代码基址和边界对将地址重新定位到正确的物理位置。如果前两位是 01,则硬件知道该地址在堆中,因此使用堆基址和边界。让我们以上面的示例堆虚拟地址 (4200) 为例并对其进行转换,只是为了确保这一点是清楚的。二进制形式的虚拟地址 4200 可以在这里看到:

从图中可以看出,前两位 (01) 告诉硬件我们正在引用哪个段。底部 12 位是段中的偏移量:0000 0110 1000,或十六进制 0x068,或十进制 104。因此,硬件只需使用前两位来确定要使用哪个段寄存器,然后将接下来的 12 位作为段中的偏移量。通过将基址寄存器与偏移量相加,硬件得出最终的物理地址。请注意,偏移量也简化了边界检查:我们可以简单地检查偏移量是否小于边界;如果不是,则该地址是非法的。因此,如果基址和边界是数组(每个段一个条目),硬件将执行类似以下操作来获取所需的物理地址:
| |
在我们的运行示例中,我们可以填写上面常量的值。具体来说,SEG MASK 将设置为 0x3000,SEG SHIFT 设置为 12,OFFSET MASK 设置为 0xFFF。您可能还注意到,当我们使用前两位时,并且只有三个段(代码、堆、栈),地址空间的一个段未被使用。因此,一些系统将代码放在与堆相同的段中,从而仅使用一位来选择要使用的段。
硬件还有其他方法来确定特定地址位于哪个段。在隐式方法中,硬件通过注意地址的形成方式来确定段。例如,如果地址是从程序计数器生成的(即,它是指令提取),则该地址在代码段内;如果地址基于栈或基址指针,则它必须位于栈段中;任何其他地址则都位于堆中。
3 关于栈
到目前为止,我们遗漏了地址空间的一个重要组成部分:栈。上图中,栈已重新定位到物理地址 28KB,但有一个关键区别:它向后增长。在物理内存中,从28KB开始,增长到26KB,对应虚拟地址16KB到14KB;地址转换必须以不同的方式进行。
我们首先需要的是一些额外的硬件支持。硬件不仅需要知道基址值和边界值,还需要知道段增长的方式(例如,当段沿正方向增长时设置为 1,当段沿负方向增长时设置为 0)。我们对硬件跟踪内容的更新视图如下表所示:
| Segment | Base | Size | Grows Positive? | Protection |
|---|---|---|---|---|
| Code | 32K | 2K | 1 | Read-Execute |
| Heap | 34K | 2K | 1 | Read-Write |
| Stack | 28K | 2K | 0 | Read-Write |
由于硬件了解段可以向负方向增长,因此硬件现在必须稍微不同地转换此类虚拟地址。让我们举一个栈虚拟地址的例子,并转换它来理解这个过程。
在此示例中,假设我们希望访问虚拟地址 15KB,该地址应映射到物理地址 27KB。我们的二进制形式的虚拟地址如下所示:11 1100 0000 0000(十六进制0x3C00)。硬件使用前两位 (11) 来指定段,但我们留下了 3KB 的偏移量。为了获得正确的负偏移量,我们必须从 3KB 中减去最大段大小:在本例中,一个段可以是 4KB,因此正确的负偏移量是 3KB 减去 4KB,等于 -1KB。我们只需将负偏移量 (-1KB) 添加到基址 (28KB) 即可得到正确的物理地址:27KB。可以通过确保负偏移的绝对值小于段的大小来计算边界检查。
4 支持段共享
随着对分段的支持不断增长,系统设计人员很快意识到,他们可以通过更多的硬件支持来实现新型效率。具体来说,为了节省内存,有时在地址空间之间共享某些内存段很有用。特别是,代码共享很常见,并且在当今的系统中仍在使用。
为了支持共享,我们需要硬件以保护位的形式提供一些额外的支持。基本支持为每个段添加一些位,指示程序是否可以读取或写入段,或者是否可以执行段内的代码。通过将代码段设置为只读,可以在多个进程之间共享相同的代码,而不必担心损害隔离性;虽然每个进程仍然认为它正在访问自己的私有内存,但操作系统正在秘密共享该进程无法修改的内存,因此保留了这种错觉。
上表显示了硬件(和操作系统)跟踪的附加信息的示例。可以看到,代码段被设置为读取和执行,因此内存中的同一物理段可以映射到多个虚拟地址空间。
有了保护位,前面描述的硬件算法也必须改变。除了检查虚拟地址是否在范围内之外,硬件还必须检查是否允许特定访问。如果用户进程尝试写入只读段,或从不可执行段执行,则硬件应引发异常,从而让操作系统处理违规进程。
5 细粒度分段与粗粒度分段
迄今为止,我们的大多数示例都集中在只有几个分段(即代码、栈、堆)的系统上;我们可以将这种分段视为粗粒度分段,因为它将地址空间分割成相对较大、较粗的块。然而,一些早期的系统(如 Multics)更加灵活,允许地址空间由大量较小的段组成,称为细粒度分段。
支持多分段需要更多硬件支持,在内存中存储某种分段表。这种段表通常支持创建大量的段,从而使系统能够以比我们迄今为止讨论的更灵活的方式使用段。例如,早期的机器(如 Burroughs B5000)支持数千个分段,并期望编译器将代码和数据切分成独立的分段,然后操作系统和硬件将支持这些分段。当时的想法是,通过细化分段,操作系统可以更好地了解哪些分段正在使用,哪些没有使用,从而更有效地利用主内存。
6 操作系统支持
您现在应该对分段的工作原理有一个基本的了解。当系统运行时,地址空间的各个部分会被重新定位到物理内存中,因此,相对于整个地址空间仅使用单个基址/边界对的更简单方法,可以节省大量物理内存。具体来说,栈和堆之间所有未使用的空间都不需要分配在物理内存中,从而允许我们将更多的地址空间放入物理内存中。
然而,分段引发了许多新问题。我们将首先描述必须解决的新操作系统问题。
第一个是旧的:操作系统在上下文切换时应该做什么?现在您应该有一个很好的猜测:必须保存和恢复段寄存器。显然,每个进程都有自己的虚拟地址空间,操作系统必须确保在让进程再次运行之前正确设置这些寄存器。
第二个也是更重要的问题是管理物理内存中的可用空间。当创建新的地址空间时,操作系统必须能够在物理内存中为其段找到空间。以前,我们假设每个地址空间的大小相同,因此物理内存可以被认为是进程可以容纳的一堆插槽。现在,每个进程有多个段,每个段可能是不同的尺寸。
出现的普遍问题是物理内存很快就会充满可用空间的小孔,使得分配新段或增加现有段变得困难。我们称这个问题为外部碎片;如下图所示(左)。
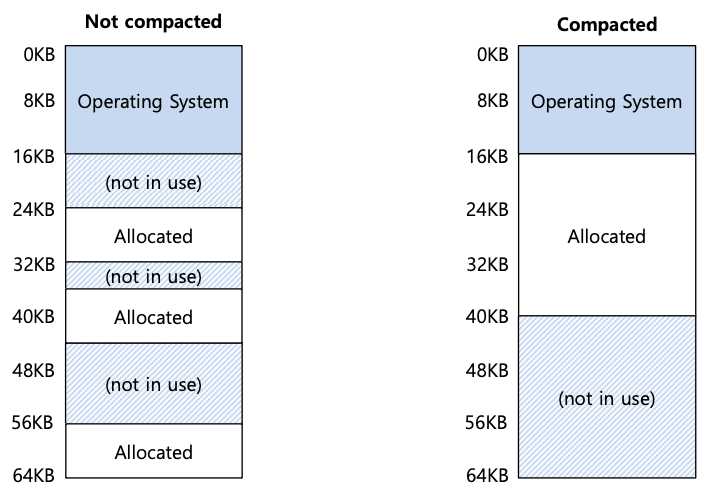
在示例中,一个进程出现并希望分配一个 20KB 的段。在该示例中,有 24KB 空闲空间,但不是在一个连续的段中(而是在三个不连续的块中)。因此,操作系统无法满足 20KB 请求。
该问题的一种解决方案是通过重新排列现有段来压缩物理内存。例如,操作系统可以停止正在运行的进程,将其数据复制到一个连续的内存区域,更改其段寄存器值以指向新的物理位置,从而拥有大量可用的可用内存。通过这样做,操作系统使新的分配请求能够成功。然而,压缩的成本很高,且因为复制段是内存密集型的,并且通常会占用相当多的处理器时间。如上图所示(右),可查看压缩物理内存后的结果。
一种更简单的方法是使用空闲列表管理算法,该算法尝试保持大范围的内存可用于分配。人们实际上已经采用了数百种方法,包括经典算法,例如最佳适应(保留可用空间列表并返回满足请求者所需分配的最接近大小的算法)、最差适应、首次适应,以及更复杂的方案,如伙伴算法 。但不幸的是,无论算法多么聪明,外部碎片仍然存在;因此,一个好的算法只是尝试将其最小化。
TIP:如果存在 1000 种解决方案,那么没有一个是最好的解决方案 存在如此多不同的算法来尝试最大限度地减少外部碎片这一事实表明了一个更强有力的潜在事实:没有一种“最佳”方法可以解决问题。因此,我们选择合理的东西,并希望它足够好。唯一真正的解决方案是完全避免这个问题,永远不要以可变大小的块分配内存。
7 总结
分段解决了许多问题,并帮助我们构建更有效的内存虚拟化。除了动态重定位之外,分段还可以通过避免地址空间的逻辑段之间潜在的巨大内存浪费来更好地支持稀疏地址空间。它也很快,因为进行算术分段所需的操作很容易并且非常适合硬件;地址转换费用很少。还出现了一个附带好处:代码共享。如果代码放置在单独的段中,则这样的段可能会在多个正在运行的程序之间共享。
然而,正如我们所知,在内存中分配可变大小的段会导致一些我们希望克服的问题。如上所述,第一个是外部碎片。因为段是可变的,所以可用内存被分成奇数大小的块,因此满足内存分配请求可能很困难。人们可以尝试使用智能算法或定期压缩内存,但问题是根本性的且难以避免。
第二个也许更重要的问题是分段仍然不够灵活,无法支持我们完全通用的稀疏地址空间。例如,如果我们在一个逻辑段中有一个大但很少使用的堆,则整个堆必须仍然驻留在内存中才能被访问。换句话说,如果我们的地址空间使用方式模型与底层分段的设计支持方式不完全匹配,分段就不能很好地工作。因此我们需要寻找一些新的解决方案。
相关内容
 支付宝
支付宝 微信
微信