【论文阅读笔记】Bigtable: A Distributed Storage System for Structured Data
1 简介
Bigtable 是 Google 设计的用于管理结构化数据的分布式存储系统,可扩展到数千台服务器存储 PB 级数据。它不是关系数据库,而是一种稀疏、分布式、持久性多维排序映射(K/V)。
Bigtable被 60 多个 Google 产品使用,涵盖不同数据规模和延迟要求的应用,这得益于 BigTable 提供的简单数据模型可以使客户端动态控制数据的布局和格式。
2 数据模型
一个 Bigtable 就是一个稀疏、分布式、持久的多维有序映射表(map),数据通过行键、列键和一个时间戳进行索引,表中的每个数据项都是不作理解的字节数组。形如:
(row:string, column:string, time:int64) -> string
假设我们想要拷贝一个可能被很多项目都使用的、很大的网页集合以及相关的信息,让我们把这个特定的表称为Webtable。在Webtable当中,我们用网页的 URL 作为行键,网页某些信息作为列键,将网页内容存储在 contents: 列,并记录抓取网页时对应的时间戳,最终存储布局如下图所示。
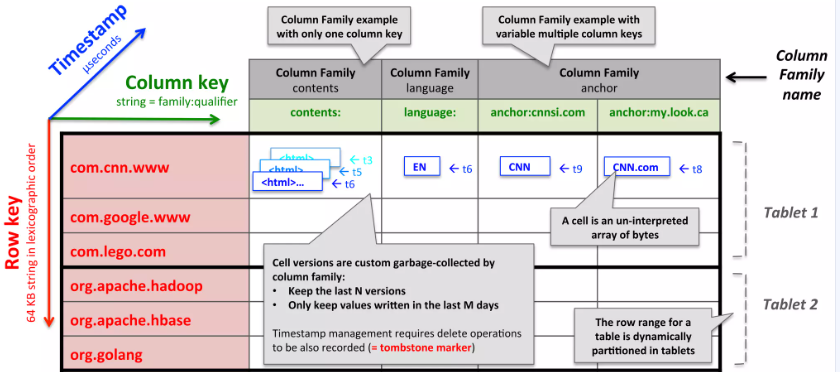
2.1 行
行键为任意字符串(最大64KB,多数用户使用的在10 - 100字节),单行数据读/写操作是原子的,这里类似Mysql的行锁,锁粒度并没有达到列级别,便于推断并发更新同一行时系统行为。
Bigtable按行键的字典序组织数据,动态划分行范围,每个行范围是一个tablet,作为请求分散和负载均衡的最小单位,这样读取小行范围高效,只需与少量机器通信,而且可以选择合适的行键有效的利用数据的位置相关性。
例如Webtable中,反转URL的hostname字段,相同域的页面存为连续行,如www.google.com存为com.google.www,可提高主机和域分析效率。
2.2 列族
多个列键可以组织成列族,列族是访问控制的基本单位。一般来说,存放在同一列族的数据通常都属于同一类型。
必须先创建一个列族,才能向这个列族内的列写入数据,创建完成后,就可以使用其中的列键。一张tablet的列族最多几百个,且很少改变,但列的数量没有限制。
列键的格式:列族:限定词。例如Webtable中有一个列族是anchor,这个列族的每一个列键代表一个锚链接,anchor列族的限定值是引用这个网页的站点名,对应的数据项内容是链接的文本。
访问控制、磁盘和内存记账都是在列族层面做的。
2.3 时间戳
Bigtable中的每个数据均可存储多个版本,不同版本通过时间戳索引。 时间戳为64位整数,可由Bigtable指定,此时为毫秒级的真实时间戳;也可由客户端应用指定,为避免冲突,应用必须确保时间戳的唯一性。
为了减轻多个版本数据的管理负担,我们对每一个列族配有两个设置参数,使Bigtable能够自动进行垃圾回收。
- 保留最后的$N$个版本;
- 保留最近某段时间内的版本。
在Webtable中,每个页面的时间戳为该页面被爬取时的时间,我们设置只保留最后的3个版本。
3 API
Bigtable API提供了创建和删除表和列族的功能。它还提供用于修改集群、表和列族元数据的功能,比如如访问控制权限。
Bigtable还支持一些其它的特性,利用这些特性,用户可以对数据进行更复杂的处理。
- 支持单行上的事务处理。
- 允许把数据项做整数计数器:
Increment(row_key, column_key, increment)。 - Bigtable允许用户在服务器地址空间上执行脚本程序。
- Bigtable提供一些Wrapper类,其可以作为MapReduce框架的输入输出。
4 基础构建
Bigtable 构建在其他几个 Google 的基础设施之上。
- GFS
- SSTable
- Chubby
4.1 GFS
Bigtable使用GFS存储日志文件和数据文件,Bigtable集群通常和其他一些分布式应用共享一个服务器资源池,依靠集群管理系统做任务调度、资源管理、故障处理和机器监控等。
4.2 SSTable
Bigtable 内部使用 Google 的 SSTable 格式存储数据。SSTable是一个持久化、排序的、不可更改的Map结构。从内部看,SSTable是一系列的数据块,并通过块索引(存储在SSTable的末尾)定位,块索引在打开SSTable时加载到内存中,一次查询只需要一次磁盘寻址:首先在内存中通过二分查找找到块索引,然后定位到数据块在磁盘中的位置,从磁盘读取相应的数据。也可以直接将整个SSTable映射到内存,这样查询就不需要磁盘操作了。

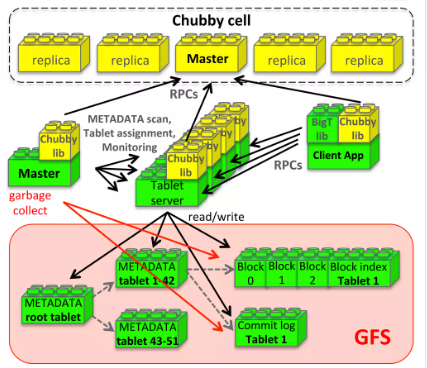
4.3 Chubby
Bigtable还依赖一个高可用的、持久的分布式锁服务Chubby(类Zookeeper)。Chubby服务维护5个活动副本,其中一个选为Master并对外提供服务,并通过Paxos算法来保证副本一致性。
另外Chubby提供一个包含目录和小文件命名空间,每个目录或文件都可以作为一个锁,读或写一个文件是原子的。Chubby客户端维护了这些文件的一致性缓存。
每个 Chubby 客户端都会和 Chubby 服务维持一个 Session。当一个客户端的租约到期 并且无法续约时,这个 Session 就失效了,失效会失去它之前的锁和打开的文件句柄。Chubby 客户端还可以在 Chubby 文件和目录上注册回调函数,当文件/目录有变化或者 Session 过期时,就会收到通知。
Bigtable使用Chubby来完成几个任务:
- 确保任意时间只有一个活动Master副本。
- 存储数据的引导位置(根tablet)。
- 发现Tablet服务器并最终确定tablet服务器死亡。
- 存储Bigtable模式信息(每个表的列族信息)。
- 存储访问控制列表等
Chubby不可用 = Bigtable不可用
5 实现
Bigtable包括3个主要的组件:
- 链接到每个客户端的库。
- 1个master服务器。
- 多个tablet服务器。
master服务器职责:
- 将tablet分配给tablet服务器。
- 检测tablet服务器的过期及添加事件。
- 对tablet服务器负载均衡。
- 对GFS中的文件的进行垃圾回收。
- 处理模式变化,如创建表、创建 / 删除列族。
tablet服务器职责:
- 管理一组tablets(10~1000个tablet)。
- 处理对 tablets 的读写请求。
- 当 tablets 增长过大(100 - 200MB)时进行分裂。
客户端不依赖master获取 tablet 位置信息,直接与 tablet 服务器进行读写通信,故Master的负载很低。
每个 Bigtable 集群会有很多张 table,每张 table 会有很多 tablets,每个 tablets 包 含一个行键范围内的全部数据。 初始时每个 table 只包含一个 tablet。当 table 逐渐变大时,它会自动分裂成多个 tablets,默认情况下每个 tablet 大约 100-200MB。
5.1 Tablet 位置
使用类似B+树的三层结构存储Tablet的位置信息,如下图所示:

- 第一层:存储在Chubby 中的文件,其中包含了根tablet的位置。所以一旦Chubby服务不可用,整个Bigtable丢失了根tablet的位置,整个服务就不可用。
- 第二层:根tablet,实际上就是元数据表的第一个tablet,保存着元数据表其他tablet的位置信息,根tablet很特殊,为了保证整个树的深度不变,根tablet从不分裂。
- 第三层:其他元数据表的tablet,每个都包含了一组用户tablet位置信息集合。这些tablet与根tablet共同构成整个元数据表。
在元数据表内,每个Tablet的位置信息都存储在一个行键下,行键是通过tablet所在表的标识符和最后一行生成的。
元数据表每一行都存储约1KB内存数据,即在一个128MB的元数据表中,采用这种3层存储结构,可寻址$2^34$个Tablets。
用户程序使用的库会缓存Tablet的位置信息,如果某个Tablet位置信息没有缓存或缓存失效,那么客户端会在树状存储结构中递归查询tablet位置信息,包括:
- 请求Chubby提供根tablet位置。
- 请求根tablet提供其他元数据tablet位置。
- 请求元数据tablet获取用户tablet位置。
尽管tablet的位置信息是存放在内存里的,对它的操作不必访问GFS文件系统,但通常还是会预取Tablet地址来进一步减少访问的开销。
5.2 Tablet 分配
每个 tablet 每次只会分配给一个 tablet服务器。这个由master来控制分配,master会跟踪:
- tablet服务器集的存活状态(通过Chubby跟踪,启动时会在在特定的 Chubby 目录下创建和获取一个名字唯一的独占锁。 master 通过监听这个目录来发现 tablet服务器集)。
- tablet到tablet服务器的当前分配。
- 当前为分配的tablet。
当某个 Tablet 未分配时,master 通过向可用的tablet服务器发送加载请求,将tablet分配给该tablet服务器。
当tablet服务器不提供服务时,master会通过轮询Chubby上tablet服务器文件锁的状态检查出来,确认后会删除其在Chubby上的文件锁,使其不再提供服务。删除后,master就把之前分配给它的所有的tablet放入未分配的tablet集合中。
当集群管理系统启动了一个master服务器之后,master首先要了解当前tablet的分配状态,之后才能够修改分配状态。master服务器在启动的时候执行以下步骤:
- 从Chubby获取一个唯一的master锁,保证Chubby只有一个master实例。
- 扫描Chubby的
servers目录,获取当前正在运行的服务器列表。 - 和所有的正在运行的tablet服务器通信,获取每个tablet服务器上tablet的分配信息。
- 扫描元数据表获取所有的tablet的集合。在扫描的过程中,如果发现还有未分配的tablet,master就将这个tablet加入未分配的tablet集合并等待合适的时机分配。
一个复杂的情况是在分配元数据tablet之前,无法对元数据表表进行扫描。
因此,如果在步骤3中发现根tablet还没有被分配出去,那master就要先把它放到未分配的tablet集合,然后去执行步骤4,这样就保证了根tablet会被分配出去。
由于根tablet包括了所有元数据tablet的名字,因此master服务器扫描完根tablet以后,就得到了所有的元数据表表的Tablet的名字了。
只有在发生以下情况时,当前的 tablets 集合才会有变化:
- 创建或删除一个 table。
- 两个 tablets 被合并了
- 一个 tablet 分裂成两个小的tablet。
Master可以跟踪记录所有这些事件,因为除了最后一个事件外的两个事件都是由它启动的。
tablet分裂事件需要特殊处理,因为它是由Tablet服务器启动。在分裂操作完成之后,tablet服务器将新的tablet信息记录到元数据表,然后提交这次分裂。提交后,master会收到通知。如果通知丢失(由于tablet服务器或者master挂掉),master会在它下次要求一个tablet服务器加载tablet时发现,这个 tablet 服务器会将这次分裂信息通知给 master,因为它在元数据表中发现的 tablets 项只覆盖 master 要求它加载的 tablets 一部分。
5.3 为 tablet 提供服务
如下图所示,Tablet的持久化状态信息保存在GFS上。

更新会提交到一个提交日志文件,其中保存了redo记录,更新操作分2类:
- 最近提交的更新操作会存放在一个排序缓存中,称为
memtable。 - 其他老一些的更新存储在 SSTable 中,落地在GFS上。
为了恢复一个tablet,tablet服务器从元数据表当中读取这个tablet的元数据。《这个元数据包含了SSTable列表,其中每个SSTable都包括一个tablet和一个重做点(redo point)的集合,这些redo point是一些指针,它们指向那些可能包含tablet所需数据的重做日志。服务器把SSTable索引读入内存,执行重做点以后的所有已经提交的更新来重建memtable。
当一个写操作到达tablet服务器时,它会检查写操作是否格式正确且发送者是否有权限执行此操作。鉴权的实现方式是从Chubby文件读取允许的写者列表,这个Chubby文件通常总能够在Chubby客户端缓存中找到。
一个有效的变更会被写入提交日志中。批量提交是为了优化许多小变更操作的吞吐量。在写操作已经被提交以后,它的内容就会被插入到memtable。
一次读操作到达 tablet server 时,也会执行类似的格式检查和鉴权。一个有效地读操作是在一系列SSTable和memtable的合并视图上执行的(都是字典序排序,可高效生成合并视图)。
当tablet发生合并或分裂操作时,正在到达的读写操作仍然可以继续进行。
5.4 压缩
####.1 小压缩
当memtable大小达到一个阈值时,memtable会被冻结,并创建一个新的memtable,这个冻结的memtable会转换为SSTable并写入GFS,这个过程称为小压缩。
小压缩过程为了减少tablet服务器的内存使用量,以及减少在灾难恢复时从提交日志读取的数据量。

####.2 主压缩
每次小压缩都会创建一个新SSTable,如果不加额外处理,SSTable数量过多而影响读操作(需要合并多个SSTable才能读到需要的内容)。所以Bigtable会定期合并SSTable文件来限制其数量,这个过程称为主压缩。

非主压缩所产生的SSTable会包含特殊的删除信息(entry),用于标记其中已经被删除的数据 —— 实际上这些数据还没有被真正删除,只是标记为已删除。而 主压缩产生的 SSTable 不会包含这些删除信息或者已删除的数据。
BigTable定期检查它的所有tablet,并执行主压缩操作。这些主压缩过程可以允许BigTable及时回收被删除数据占用的资源,并且保证被删除数据在一定时间内就可以及时的从系统中消失,这对于一些存储敏感数据的服务来说是非常重要的。
6 优化
6.1 局部性组
客户端可以将多个列族组合成一个局部性组,每个tablet会为每个局部性组生成一个单独的SSTable,将一般不会一起访问的列族划分到不同的局部性组能提高读取效率。
此外,可以基于局部性组专门设定一些调优参数,如是否存储于内存等。
6.2 压缩
客户端可以控制某个局部性组的SSTable 是否需要压缩,以及用什么格式压缩。很多客户端都使用一种自定义的双通压缩算法:
- 先使用 Bentley-Mcilroy 算法压缩大窗口内的长公共前缀。
- 再使用一个快速算法压缩 16KB 窗口内的重复字符串。
6.3 缓存
tablet服务器可以使用二级缓存策略来提高读操作性能。两级的缓存针对性不同:
- 第一级缓存为扫描缓存:缓存tablet服务器通过SSTable接口获取的Key-Value对(时间局部性:适用于频繁访问相同数据的应用)
- 第二级缓存为块缓存:缓存从GFS读取的SSTable块(空间局部性:适用于连续访问相邻(相近)数据的应用。)

6.4 布隆过滤器
一个读操作必须读取构成tablet状态的所有SSTable数据,故如果这些SSTable不在内存便需多次访问磁盘。我们通过允许客户端对特定局部性组的SSTable指定布隆过滤器来降低访问次数。Bloom 过滤器可以判断一个 SSTable 是否包含指定行/列对对应的 数据。对于特定的应用来说,给 tablet服务器增加少量内存用于存储 Bloom 过滤器,就 可以极大地减少读操作的磁盘访问。
使用Bloom过滤器也可以隐式的达到了当查询的行和列不存在时,不需要访问磁盘。
6.5 Commit日志实现
如果每个tablet操作的Commit日志单独写一个文件,会导致日志文件数过多,会导致底层 GFS 大量文件的并发写。另外,每个 tablet 一个 log 文件的设计还会降低组提交(group commit,批量提交)优化的有效性,因为每个组都会很小。
因此,为了克服以上问题,我们为每个 tablet服务器维护一个commit log,将属于这个 tablet服务器的不同的 tablet 操作都写入这同一个物理上的 log 文件。
这种方式使得常规操作的性能得到了很大提升,但是,它使 tablet 恢复过程变得复杂。当一台tablet服务器挂了,需要将其上面的tablet均匀恢复到其他Tablet服务器,则其他服务器都得读取完整的Commit日志。

为了避免多次读Commit日志,我们将日志按关键字(table; row name; log sequence number)排序,让同一个tablet的操作日志连续存放。
6.6 Tablet恢复提速
master转移Tablet时,源tablet服务器会对这个Tablet做一次小压缩,在此压缩后,源tablet服务器停止为tablet服务。在卸载tablet之前,源tablet服务器会执行另一个(非常快)的小压缩,以消除在第一个小压缩时到达的tablet服务器日志中任何未经压缩的状态。然后tablet就可以装载到新的tablet服务器上了,并且不需要从日志中进行恢复。
6.7 利用不变性
由于生成的所有SSTables都是不可变的,因此Bigtable系统的各个部分都得到了简化。
- 从SStable读取时无需同步$\rightarrow$对行进行简单的并发控制。
- 读取和写入访问的唯一可变数据结构是
memtable$\rightarrow$每个memtable行使用写时复制并允许读取和写入并行进行。 - 每个 tablet 的 SSTable 会注册到元数据表。master 会对过期的 SSTable 进行先标记后清除,其中元数据表记录了这些 SSTable 的对应的 tablet 的 root。
- 最后,SSTable 的不可变性使得 tablet 分裂过程更快。我们直接让子 tablet 共享父 tablet 的 SSTable ,而不是为每个子 tablet 分别创建一个新的 SSTable。
相关内容
- 【论文阅读笔记】The Chubby Lock Service for Loosely-Coupled Distributed Systems
- 【MIT 6.5840(6.824) 】Lab3:Raft 设计实现
- 【MIT 6.5840(6.824)学习笔记】 测试分布式系统的线性一致性
- 【论文阅读笔记】MapReduce: Simplified Data Processing on Large Clusters
- 【论文阅读笔记】The Google File System
 支付宝
支付宝 微信
微信