高级页表
现在我们解决分页带来的第二个问题:页表太大,因此消耗太多内存。让我们从线性页表开始。您可能还记得,线性页表变得相当大。再次假设 32 位地址空间($2^{32}$字节),具有 4KB($2^{12}$ 字节)页面和 4 字节页表条目。因此,地址空间中大约有一百万个虚拟页($\frac{2^{32}}{2^{12}}$);乘以页表条目大小,您会看到页表大小为 4MB。

另回想一下:我们通常为系统中的每个进程都有一个页表!对于一百个活动进程(在现代系统上并不罕见),我们将为页表分配数百兆字节的内存!因此,我们正在寻找一些技术来减轻这种沉重的负担。它们有很多,所以让我们开始吧。但在之前我们的问题关键是:简单的基于数组的页表(通常称为线性页表)太大,在典型系统上占用太多内存。如何才能让页表变小呢?关键的想法是什么?这些新的数据结构会导致哪些低效率?
1 简单的解决方案:更大的页面
我们可以通过一种简单的方法来减小页表的大小:使用较大的页面。再次使用我们的 32 位地址空间,但这次假设页面为 16KB。因此,我们将拥有一个 18 位 VPN 加上一个 14 位偏移量。假设每个 PTE 的大小相同(4 字节),我们的线性页表中现在有 $2^{18}$ 个条目,因此每个页表的总大小为 1MB,页表大小减少了四倍(毫不奇怪,减少恰好反映了页面大小四倍的增加)。

然而,这种方法的主要问题是大页面会导致每个页面内的浪费,这个问题称为内部碎片(因为浪费是分配单元内部的)。因此,应用程序最终会分配页面,但只使用每个页面的一小部分,并且内存很快就会被这些过大的页面填满。因此,大多数系统在常见情况下使用相对较小的页面大小:4KB(如在 x86 中)或 8KB(如在 SPARCv9 中)。我们的问题不会这么简单地解决。
2 混合方法:分页和分段
每当你对生活中的某件事有两种合理但不同的方法时,你应该始终检查两者的结合,看看是否能获得两全其美的效果。我们将这种组合称为混合体。
多年前,Multics 的创建者(特别是 Jack Dennis)在构建 Multics 虚拟内存系统时偶然想到了这样的想法。具体来说,Dennis 提出了将分页和分段相结合的想法,以减少页表的内存开销。通过更详细地检查典型的线性页表,我们可以明白为什么这可能起作用。假设我们有一个地址空间,其中堆和栈的已使用部分很小。例如,如下图所示,我们使用 16KB 的微小地址空间和 1KB 页面;
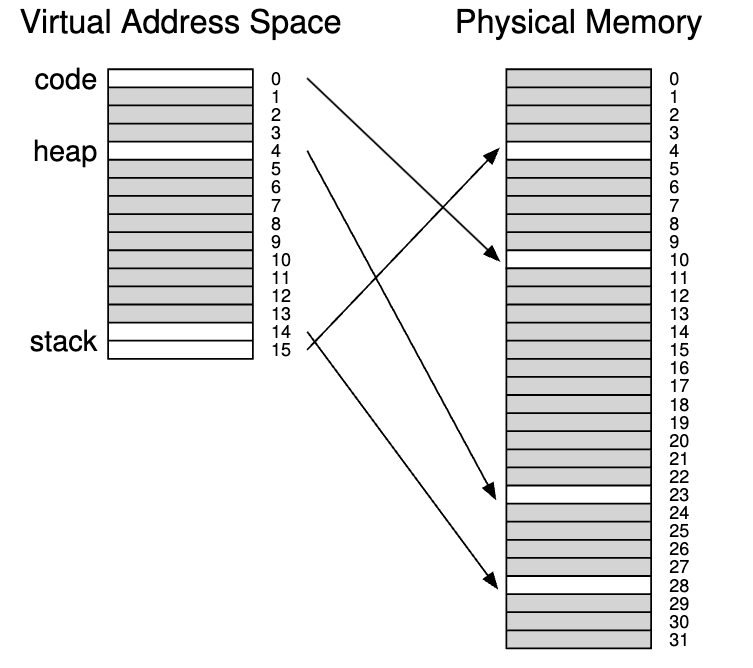
该地址空间的页表如图下图所示。
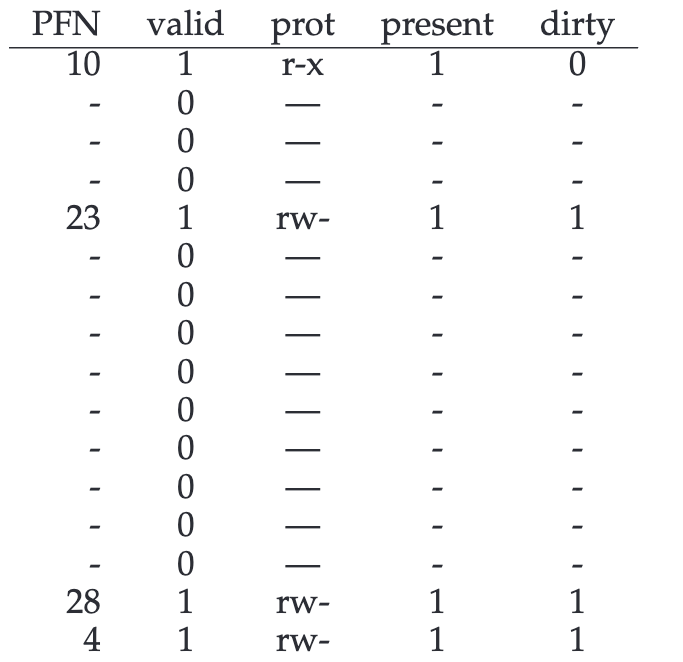
本例假定单个代码页(VPN 0)映射到物理页 10,单个堆页(VPN 4)映射到物理页 23,地址空间另一端的两个栈页(VPN 14 和 15)分别映射到物理页 28 和 4。从图中可以看出,大部分页表都未使用,充满了无效条目。非常浪费空间,且这只是一个 16KB 的小地址空间,如果是32位,会浪费的更多。
因此,我们的混合方法是:与其为进程的整个地址空间制作一个页表,为什么不为每个逻辑段制作一个页表呢?在这个例子中,我们可能会有三个页表,分别用于地址空间的代码、堆和栈部分。
现在,请记住分段,我们有一个基址寄存器告诉我们每个段在物理内存中的位置,还有一个边界或限制寄存器告诉我们所述段的大小。在我们的混合中,我们在 MMU 中仍然有这些结构;在这里,我们使用基址不是指向段本身,而是保存该段页表的物理地址。边界寄存器用于指示页表的末尾(即,它有多少个有效页)。
让我们举一个简单的例子来说明。假设 32 位虚拟地址空间有 4KB 页面,地址空间分为四个段。在本例中,我们只使用三个段:一个用于代码,一个用于堆,一个用于栈。
为了确定地址引用哪个段,我们将使用地址空间的前两位。假设 00 是未使用的段,01 表示代码,10 表示堆,11 表示堆栈。因此,虚拟地址如下所示:

在硬件中,假设有三个基寄存器/边界对,代码、堆和栈各一个。当进程运行时,每个分段的基寄存器都包含该分段线性页表的物理地址;因此,系统中的每个进程现在都有三个与之相关的页表。在上下文切换时,必须更改这些寄存器,以反映新运行进程的页表位置。
在 TLB 未命中时(假设 TLB 由硬件管理,即由硬件负责处理 TLB 未命中),硬件会使用段位(SN)来确定要使用的基址和边界对。然后,硬件将其中的物理地址与 VPN 进行如下组合,形成页表项 (PTE) 的地址:
| |
这个序列看起来应该很熟悉;它实际上与我们之前看到的线性页表相同。当然,唯一的区别是使用三个段基址寄存器之一而不是单页表基址寄存器。
我们的混合方案的关键区别是每个段都存在一个边界寄存器;每个边界寄存器保存段中最大有效页的值。例如,如果代码段正在使用其前三页(0、1 和 2),则代码段页表将仅分配有三个条目,并且边界寄存器将设置为 3;超出段末尾的内存访问将生成异常,并可能导致进程终止。通过这种方式,与线性页表相比,我们的混合方法实现了显著的内存节省;栈和堆之间未分配的页面不再占用页表中的空间(只是将它们标记为无效)。
然而,正如您可能注意到的,这种方法并非没有问题。首先,它仍然需要我们使用分段;正如我们之前讨论的,分段并不像我们希望的那么灵活,因为它假设地址空间有某种使用模式;例如,如果我们有一个大但很少使用的堆,我们仍然可能会产生大量页表浪费。其次,这种混合导致外部碎片再次出现。虽然大多数内存都是以页大小为单位进行管理的,但页表现在可以是任意大小(PTE 的倍数)。因此,在内存中为它们找到可用空间更加复杂。由于这些原因,人们不断寻找更好的方法来实现更小的页表。
3 多级页表
3.1 介绍
另一种方法不依赖于分段,但解决了同样的问题:如何摆脱页表中的所有无效区域,而不是将它们全部保留在内存中?我们将这种方法称为多级页表,因为它将线性页表变成了类似树的东西。这种方法非常有效,以至于许多现代系统都采用它(例如 x86 [BOH10])。我们现在详细描述这种方法。
多级页表背后的基本思想很简单。首先,将页表切分成页大小的单元;然后,如果页表条目 (PTE) 的整个页无效,则根本不分配页表的该页。要跟踪页表的页面是否有效(以及如果有效,则它在内存中的位置),则使用称为页目录的新结构。因此,页目录可以用来告诉您页表的某个页在哪里,或者页表的整个页不包含有效页。
下图展示了一个示例。图左边是经典的线性页表;即使地址空间的大多数中间区域无效,我们仍然需要为这些区域分配页表空间(即页表的中间两页)。右边是多级页表。页目录仅将页表的两页标记为有效(第一页和最后一页);因此,只有页表的那两页驻留在内存中。因此,您可以看到一种可视化多级表正在执行的操作的方法:它只是使部分线性页表消失(释放这些页以供其他用途),并跟踪页表的哪些页分配了该页目录。

页目录在一个简单的两级表中,页表的每一页包含一个条目。它由许多页目录项(PDE)组成。 PDE(至少)具有有效位和物理页框号 (PFN),与 PTE 类似。然而,正如上面所暗示的,该有效位的含义略有不同:如果 PDE 有效,则意味着该条目(通过 PFN)指向的页表中的至少一页是有效的,即,在该PDE指向的该页上的至少一个PTE中,该PTE中的有效位被设置为1。如果 PDE 无效(即等于 0),则 PDE 的其余部分未定义。
与我们迄今为止看到的方法相比,多级页表具有一些明显的优势。首先,也许最明显的是,多级表仅根据您正在使用的地址空间量按比例分配页表空间;因此它通常是紧凑的并且支持稀疏地址空间。
其次,如果精心构建,页表的每个部分都可以整齐地容纳在一个页面中,从而更容易管理内存;当操作系统需要分配或增长页表时,它可以简单地获取下一个空闲页面。将此与简单(非分页)线性页表 进行对比,后者只是由 VPN 索引的 PTE 数组;采用这样的结构,整个线性页表必须连续地驻留在物理内存中。对于大页表(例如 4MB),找到这么大块未使用的连续空闲物理内存可能是一个相当大的挑战。对于多级结构,我们通过使用页目录来添加间接层,页目录指向页表的各个部分;这种间接允许我们将页表页面放置在物理内存中的任何位置。
需要注意的是,多级表是有成本的;如果 TLB 未命中,则需要从内存加载两次才能从页表获取正确的转换信息(一次用于页目录,一次用于 PTE 本身),而线性页表只需加载一次。因此,多级表是时空权衡的一个小例子。我们想要更小的表(并且得到了),但不是免费的;虽然在常见情况下(TLB 命中),性能显然是相同的,但是对于这个较小的表,TLB 未命中会遭受更高的成本。
另一个明显的负面因素是复杂性。无论是硬件还是操作系统处理页表查找(在 TLB 未命中时),这样做无疑比简单的线性页表查找更复杂。通常我们愿意增加复杂性以提高性能或减少开销;对于多级表,我们使页表查找更加复杂,以节省宝贵的内存。
3.2 多级页表示例
为了更好地理解多级页表背后的想法,让我们举一个例子。想象一个大小为 16KB、具有 64 字节页面的小地址空间。因此,我们有一个 14 位虚拟地址空间,其中 8 位用于 VPN,6 位用于偏移量。即使仅使用一小部分地址空间,线性页表也将具有 $2^8$ (256) 个条目。下图展示了此类地址空间的一个示例。

在此示例中,虚拟页 0 和 1 用于代码,虚拟页 4 和 5 用于堆,虚拟页 254 和 255 用于堆栈;地址空间的其余页面未使用。
为了为此地址空间构建两级页表,我们从完整的线性页表开始,并将其分解为页面大小的单元。回想一下我们的完整表(在本例中)有 256 个条目;假设每个 PTE 的大小为 4 字节。因此,我们的页表大小为 1KB(256 × 4 字节)。假设我们有64字节的页面,那么1KB的页表可以分为16个64字节的页面;每页可容纳 16 个 PTE。
我们现在需要了解的是如何使用VPN并使用它首先索引到页目录,然后索引到页表的页面。请记住,每个都是一个条目数组;因此,我们需要弄清楚的是如何为 VPN 的每个部分构建索引。
让我们首先索引到页面目录。本例中的页表很小:256 个条目,分布在 16 个页面上。页目录需要页表的每一页一个条目;因此,它有 16 个条目。因此,我们需要 VPN 的四位来索引目录;我们使用VPN的前四位,如下:

一旦我们从VPN中提取出页目录索引(简称PDIndex),我们就可以通过简单的计算来找到页目录条目(PDE)的地址: PDEAddr = PageDirBase + (PDIndex * sizeof(PDE) )。这就产生了我们的页面目录,现在我们对其进行研究,以进一步推进我们的转换工作
如果页目录条目被标记为无效,我们就知道访问无效,从而引发异常。然而,如果PDE有效,我们还有更多工作要做。具体来说,我们现在必须从该页目录项指向的页表页中获取页表项(PTE)。为了找到这个 PTE,我们必须使用 VPN 的剩余位来索引页表的部分:

然后可以使用此页表索引(简称 PTIndex)对页表本身进行索引,从而为我们提供 PTE 的地址:
PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))
请注意,从页目录项获得的物理页框号 (PFN) 必须先左移到位,然后才能与页表索引组合以形成 PTE 的地址。为了看看这一切是否有意义,我们现在将用一些实际值填充多级页表,并转换单个虚拟地址。让我们从本例的页面目录开始(如下图左侧)。

在图中,您可以看到每个页目录项 (PDE) 描述了有关地址空间页表中的一页的信息。在此示例中,我们在地址空间中有两个有效区域(位于开头和结尾),以及中间的许多无效映射。在物理页100(页表第0页的物理帧号)中,我们有地址空间中前16个VPN的16个页表条目的第一页。这部分页表的内容见上图(中间部分)。
页表的该页包含前 16 个 VPN 的映射;在我们的示例中,VPN 0 和 1 有效(代码段),4 和 5(堆)也是有效的。因此,该表具有每个页面的映射信息。其余条目被标记为无效。
页表的另一个有效页位于 PFN 101 内。该页包含地址空间最后 16 个 VPN 的映射;如上图所示(右)。
在示例中,VPN 254 和 255(堆栈)具有有效映射。希望我们可以从这个示例中看到,使用多级索引结构可以节省多少空间。在此示例中,我们没有为线性页表分配完整的 16 个页面,而是仅分配三个页面:一个用于页目录,两个用于具有有效映射的页表块。对于大型(32 位或 64 位)地址空间来说,节省的成本显然要大得多。
最后,让我们使用这些信息来执行转换。这是一个引用 VPN 254 第 0 个字节的地址:0x3F80,或二进制的 11 1111 1000 0000。
回想一下,我们将使用 VPN 的前 4 位来索引页面目录。因此,1111 将选择上面页目录的最后一个(如果从第 0 个开始,则为第 15 个)条目。这将我们指向位于地址 101 的页表的有效页面。然后,我们使用 VPN (1110) 的接下来 4 位来索引页表的该页面并找到所需的 PTE。 1110 是页面上的倒数第二个(第 14 个)条目,它告诉我们虚拟地址空间的第 254 页映射到物理页 55。通过将 PFN=55(或十六进制 0x37)与 offset=000000 连接,我们因此可以形成我们想要的物理地址并向内存系统发出请求:PhysAddr = (PTE.PFN << SHIFT) + offset = 00 1101 1100 0000 = 0x0DC0。您现在应该了解如何使用指向页表页面的页目录来构造两级页表。然而不幸的是,我们的工作还没有完成。正如我们现在将讨论的,有时两级页表是不够的!
3.3 不止两级
到目前为止,在我们的示例中,我们假设多级页表只有两个级别:页目录,然后是页表的各个部分。在某些情况下,更深的树是可能的(而且确实是需要的)。
让我们举一个简单的例子,并用它来说明为什么更深的多级表会很有用。在此示例中,假设我们有一个 30 位虚拟地址空间和一个小(512 字节)页面。因此,我们的虚拟地址有一个 21 位虚拟页号组件和一个 9 位偏移量。
请记住我们构建多级页表的目标:使页表的每一部分都适合单个页面。到目前为止,我们只考虑了页表本身;但是,如果页面目录变得太大怎么办?
为了确定多级表中需要多少级才能使页表的所有部分都适合一个页面,我们首先确定一个页面适合多少个页表条目。鉴于我们的页面大小为 512 字节,并假设 PTE 大小为 4 字节,您应该会发现单个页面上可以容纳 128 个 PTE。当我们对页表的某个页面进行索引时,我们可以得出结论,我们需要 VPN 的最低有效 7 位 ($\log _2{128}$) 作为索引:

从上图中您还可能注意到,(大)页目录中还剩下多少位: 14。如果我们的页目录有 $2^{14}$个条目,那么它跨越的不是一页而是 128,因此,我们将多级页表的每一部分都放入一个页面的目标就消失了。
为了解决这个问题,我们通过将页面目录本身拆分为多个页面来构建树的更高级别,然后在其顶部添加另一个页面目录,以指向页面目录的页面。因此,我们可以将虚拟地址拆分如下:
 现在,在索引上层页面目录时,我们使用虚拟地址的最顶层位(图中的 PD 索引 0);该索引可用于从上层页面目录中获取页面目录条目。如果有效,则结合顶层 PDE 的物理页号和 VPN 的下一部分(PD 索引 1),查询页面目录的第二层。最后,如果有效,就可以使用页表索引与二级 PDE 中的地址相结合,形成 PTE 地址。啧啧这可是个大工程。而这一切仅仅是为了在多级表中查找某个内容。
现在,在索引上层页面目录时,我们使用虚拟地址的最顶层位(图中的 PD 索引 0);该索引可用于从上层页面目录中获取页面目录条目。如果有效,则结合顶层 PDE 的物理页号和 VPN 的下一部分(PD 索引 1),查询页面目录的第二层。最后,如果有效,就可以使用页表索引与二级 PDE 中的地址相结合,形成 PTE 地址。啧啧这可是个大工程。而这一切仅仅是为了在多级表中查找某个内容。
3.4 转换过程:记住 TLB
为了总结使用二级页表进行地址转换的整个过程,我们再次以算法形式呈现控制流,如下面这段代码所示。
| |
该段代码显示了每次内存引用时硬件(假设有硬件管理的 TLB)中发生的情况。从代码中可以看出,在任何复杂的多级页表访问发生之前,硬件首先会检查TLB;一旦命中,物理地址就直接形成,而无需像以前一样访问页表。仅当 TLB 未命中时,硬件才需要执行完整的多级查找。在此路径上,您可以看到传统两级页表的成本:两次额外的内存访问来查找有效的转换。
3.5 真实的多级页表
真实多级页面表($2^{48}$B=256TB)
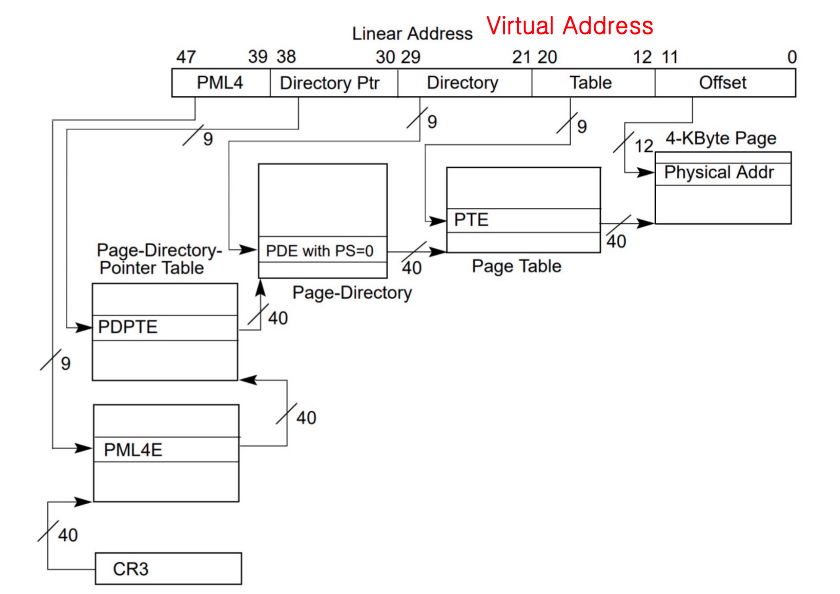
如上图所示,线性地址的结构包含48位,这些位被划分为几个关键部分,每部分负责指向下一级的内存映射结构或确定页内的偏移量。
- PML4 (Page Map Level 4): 线性地址的最高9位(位39-47)用于索引PML4(Page Map Level 4)表。PML4表是一个包含着页映射表指针的数组,每个指针指向一个页目录指针表(PDPT)。
- Directory Pointer (PDPT): 接下来的9位(位30-38)用于在PDPT中索引一个条目,该条目指向一个页目录。
- Directory (PD): 紧接着的9位(位21-29)用于在页目录中索引一个条目,该条目指向一个页表。
- Page Table (PT): 再下来的9位(位12-20)用于在页表中索引一个页表项(PTE),该页表项包含了最终物理页面的地址信息。
- Page Offset: 最后的12位(位0-11)是页内偏移量,用于确定在物理页面内的具体地址。
通过这种分层的索引机制,操作系统可以从线性地址生成对应的物理地址,从而允许更有效地管理内存,并实现诸如虚拟内存和内存保护等高级功能
自2021年起($2^{56}$B=128PB)
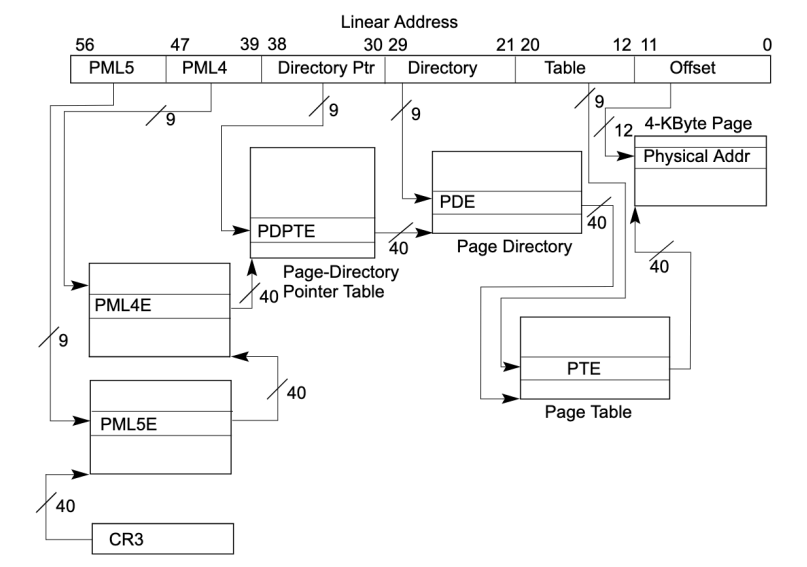
相比之前的48位线性地址结构,现在的线性地址结构包含57位,多出了一个PML5级别,这使得页表层次结构更加深入,从而能够管理更大的地址空间。PML5 (Page Map Level 5): 新增的最高9位(位48-56)用于索引PML5表。PML5表是一个包含着页映射表指针的数组,每个指针指向一个PML4表。这一级页表的存在允许系统支持更大的物理内存,因为它增加了地址转换的层次,使得能够映射的地址空间成倍增长。PML5的引入进一步扩展了这种机制,使得系统能够处理更多的内存,这对于现代计算机系统处理大量数据和运行大型应用程序是非常重要的。
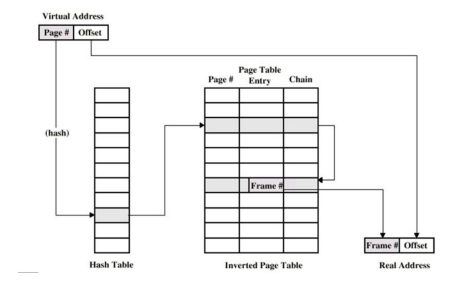
4 反向页表
在页表的世界里,反向页表可以节省更多的空间。在这种情况下,我们不需要许多页表(系统的每个进程一个),而只需保存一个页表,该页表为系统的每个物理页提供一个条目。这个条目告诉我们哪个进程在使用这个页面,以及该进程的哪个虚拟页面映射到这个物理页面。
要找到正确的条目,只需在这个数据结构中进行搜索。线性扫描的成本很高,因此通常会在基础结构上建立一个哈希表,以加快查找速度。PowerPC 就是这种架构的一个例子。
更广泛地说,反向页表说明了我们从一开始就说过的:页表只是一种数据结构。你可以用数据结构做很多疯狂的事情,让它们变小或变大,变慢或变快。多级页表和倒转页表只是其中的两个例子。
5 将页表交换到磁盘
最后,我们讨论放宽最后一个假设的问题。到目前为止,我们一直假设页表位于内核所有的物理内存中。即使我们采用了许多技巧来缩小页表的大小,但仍有可能出现页表过大,无法一次性放入内存的情况。因此,有些系统会将这些页表放在内核虚拟内存中,这样当内存压力有点紧张时,系统就可以将其中一些页表交换到磁盘上。我们将在以后的章节(即有关 VAX/VMS 的案例研究)中进一步讨论这个问题,届时我们将更详细地了解如何将页面移入和移出内存。



相关内容
 支付宝
支付宝 微信
微信