快速文件系统
1 旧Unix操作系统的问题
UNIX 操作系统问世之初,UNIX奇才Ken Thompson自己编写了第一个文件系统。我们称之为 “老 UNIX 文件系统”,它非常简单。基本上,它的数据结构在磁盘上看起来是这样的:

超级块 (S) 包含有关整个文件系统的信息:卷有多大、有多少 inode、指向空闲块列表头部的指针等等。磁盘的inode区域包含文件系统的所有inodes。最后,大部分磁盘都被数据块占用了。
旧文件系统的好处是它很简单,并且支持文件系统试图提供的基本抽象:文件和目录层次结构。这个易于使用的系统是从过去笨拙的、基于记录的存储系统向前迈出的真正一步,并且目录层次结构相对于早期系统提供的更简单的单级层次结构来说是真正的进步。
问题是:性能非常糟糕。根据 Kirk McKusick 和他在伯克利的同事的测量,性能从一开始就很糟糕,而且随着时间的推移越来越差,到后来文件系统只能提供整个磁盘带宽的 2%!
主要问题在于,旧的 UNIX 文件系统把磁盘当作随机存取存储器来处理;数据被分散到各个地方,而不考虑保存数据的介质是磁盘这一事实,因此有实际而昂贵的定位成本。例如,一个文件的数据块往往离其 inode 很远,因此每当先读取 inode,然后再读取文件的数据块时,都会产生昂贵的寻道(这是一个相当常见的操作)。
更糟糕的是,由于没有对空闲空间进行仔细管理,文件系统最终会变得相当碎片化。空闲列表最终会指向散布在磁盘上的大量区块,当文件被分配时,它们只会占用下一个空闲区块。其结果是,逻辑上连续的文件会在磁盘上来回访问,从而大大降低了性能。例如,假设下面的数据块区域包含四个文件(A、B、C 和 D),每个文件的大小为 2 个数据块:

如果删除 B 和 D,则结果布局为:

正如你所看到的,空闲空间被分割成两块,每块两个区块,而不是一块连续的四个区块。假设你现在想分配一个四块大小的文件 E:

你可以看到发生了什么:E 会被分散到整个磁盘,因此在访问 E 时,磁盘的性能不会达到峰值(顺序)。而是先读取 E1 和 E2,然后寻道,再读取 E3 和 E4。这种碎片问题在旧的 UNIX 文件系统中经常出现,而且会影响性能。顺便提一句:磁盘碎片整理工具正是用来解决这个问题的;它们会重组磁盘上的数据,将文件连续放置,并为一个或几个连续区域腾出空间,移动数据,然后重写 inodes 等,以反映变化。
还有一个问题:原始块大小太小(512 字节)。因此,从磁盘传输数据的效率本来就不高。块越小越好,因为可以最大限度地减少内部碎片(块内的浪费),但对传输不利,因为每个块都可能需要定位开销才能到达。这就是问题所在:
如何组织文件系统数据结构以提高性能?在这些数据结构之上,我们需要哪种类型的分配策略?如何让文件系统 “感知磁盘”?
2 FFS:磁盘感知是解决方案
伯克利大学的一个小组决定建立一个更好、更快的文件系统,他们巧妙地将其称为快速文件系统(FFS)。他们的想法是设计 “磁盘感知 “的文件系统结构和分配策略,从而提高性能,他们正是这样做的。因此,FFS 开启了文件系统研究的新纪元;通过保留文件系统的相同接口(相同的 API,包括 open()、read()、write()、close() 和其他文件系统调用),但改变内部实现,作者为新文件系统的构建铺平了道路,这项工作一直持续到今天。几乎所有现代文件系统都遵循现有的接口(从而保持与应用程序的兼容性),同时出于性能、可靠性或其他原因改变其内部结构。
3 组织结构:柱面组
第一步是更改磁盘结构。 FFS 将磁盘划分为多个柱面组。单柱面是硬盘驱动器不同表面上距驱动器中心距离相同的一组磁道;它被称为柱面是因为它与所谓的几何形状明显相似。 FFS将N个连续的柱面聚合为一组,因此整个磁盘可以被视为柱面组的集合。这是一个简单的示例,显示了具有六个盘片的驱动器的四个最外层磁道,以及由三个柱面组成的柱面组:

请注意,现代驱动器不会导出足够的信息供文件系统真正理解特定柱面是否正在使用;如前所述,磁盘导出块的逻辑地址空间,并将其几何细节隐藏在客户端之外。因此,现代文件系统(例如Linux ext2、ext3和ext4)将驱动器组织成块组,每个块组只是磁盘地址空间的连续部分。下面的图片说明了一个示例,在该示例中,每8个块被组织到不同的块组中(请注意实际分组将包含更多块)。

无论您将它们称为柱面组还是块组,这些组都是 FFS 用于提高性能的核心机制。至关重要的是,通过将两个文件放在同一组中,FFS 可以确保依次访问不会导致磁盘上的长时间查找。
为了使用这些组来存储文件和目录,FFS 需要能够将文件和目录放入一个组中,并在其中跟踪有关它们的所有必要信息。为此,FFS 包含您可能期望文件系统在每个组中具有的所有结构,例如 inode 空间、数据块以及一些用于跟踪这些结构是否已分配或空闲的结构。以下是 FFS 在单个柱面组中保留的内容的描述:

现在让我们更详细地检查一下这个单个柱面组的组成部分。出于可靠性原因,FFS 会在每个组中保留一份超级块 (S) 副本。挂载文件系统需要超级块;通过保留多个副本,如果其中一个副本损坏,你仍然可以通过工作副本挂载和访问文件系统。
在每个组内,FFS 需要跟踪该组的 inode 和数据块是否已分配。每个组的 inode 位图 (ib) 和数据位图 (db) 对每个组中的 inode 和数据块起作用。位图是管理文件系统中空闲空间的绝佳方法,因为很容易找到一大块空闲空间并将其分配给文件,或许可以避免旧文件系统中空闲列表的一些碎片问题。
最后,inode 和数据块区域与以前的 “非常简单文件系统”(VSFS)一样。像往常一样,每个柱面组的大部分由数据块组成。
FFS 文件创建 作为一个例子,想一想创建文件时必须更新哪些数据结构;在这个例子中,假设用户创建了一个新文件
/foo/bar.txt,文件长度为一个块(4KB)。该文件是新文件,因此需要一个新的 inode;因此,inode 位图和新分配的 inode 都将被写入磁盘。文件中还有数据,因此也必须分配;数据位图和数据块(最终)将被写入磁盘。因此,对当前分区至少要进行四次写入(请注意,这些写入在进行之前可能会在内存中缓冲一段时间)。但这还不是全部!尤其是,在创建新文件时,还必须将文件放到文件系统的层次结构中,即必须更新目录。具体来说,必须更新父目录
foo,以添加bar.txt条目;这一更新可能适合foo的现有数据块,也可能需要分配一个新块(以及相关的数据位图)。foo的 inode 也必须更新,以反映目录的新长度并更新时间字段(如最后修改时间)。总的来说,创建一个新文件的工作量很大!也许下次再创建新文件时,你应该更加感激,或者至少对创建工作如此顺利感到惊讶。
4 策略:如何分配文件和目录
有了这个组结构,FFS 现在必须决定如何将文件和目录以及相关元数据放置在磁盘上以提高性能。基本原则很简单:将相关的东西放在一起(其推论就是将不相关的东西分开)。
因此,为了遵守这一原则,FFS 必须决定什么是“相关的”并将其放置在同一个区块组中;相反,不相关的项目应放置在不同的块组中。为了实现这一目标,FFS 使用了一些简单的放置启发式法。
首先是目录的放置。 FFS 采用一种简单的方法:找到分配目录数量较少(以平衡组之间的目录)和空闲 inode 数量较多(以便随后能够分配一堆文件)的柱面组,并将目录数据和inode放在该组中。当然,这里可以使用其他启发式方法(例如,考虑空闲数据块的数量)。
对于文件,FFS 做了两件事。
- 首先,它确保(在一般情况下)将文件的数据块分配在与其 inode 相同的组中,从而防止 inode 和数据之间的长时间查找(如在旧文件系统中)。
- 其次,它将同一目录中的所有文件放置在它们所在目录的柱面组中。
因此,如果用户创建四个文件:/a/b、/a/c、/a/d 和 b/ f,FFS 会尝试将前三个放置在彼此附近(同一组),而第四个放置在远处(在其他组中)。
让我们看一个此类分配的示例。在示例中,假设每组只有 10 个 inode 和 10 个数据块(都小得离谱),并且三个目录(根目录 /、/a、/b)和 4 个文件(/a/ c、/a/d、/a/e、/b/f) 根据 FFS 策略放置在其中。假设常规文件的大小各为两个块,并且目录只有一个数据块。对于该图,我们对每个文件或目录使用明显的符号(即 / 表示根目录,a 表示 /a,f 表示 /b/f,等等)。

请注意,FFS 策略做了两个积极的事情:每个文件的数据块都靠近每个文件的 inode,同一目录中的文件彼此靠近(即 /a/c、/a/d 和 /a/e)都在组 1 中,并且目录 /b 及其文件 /b/f 在组 2 中彼此靠近)。
相比之下,现在让我们看一下 inode 分配策略,它只是将 inode 分布在组之间,试图确保没有组的 inode 表很快被填满。最终的分配可能如下所示:

从图中可以看出,虽然此策略确实将文件(和目录)数据保留在其各自的 inode 附近,但目录中的文件在磁盘上任意分布,因此不会保留基于名称的局部性。对文件 /a/c、/a/d 和 /a/e 的访问现在跨越三组,而不是按照 FFS 方法跨越一组。
FFS 策略启发式方法并非基于对文件系统流量或任何特别细微的内容的广泛研究;相反,它们基于良好的老式常识。目录中的文件通常一起访问:想象一下编译一堆文件,然后将它们链接到单个可执行文件中。由于存在这种基于命名空间的局部性,FFS 通常会提高性能,确保相关文件之间的查找良好且简短。
5 文件局部性测量
为了更好地理解这些启发式方法是否有意义,让我们分析一些文件系统访问的痕迹,看看是否确实存在命名空间局部性。由于某种原因,文献中似乎没有对这个主题进行很好的研究。
具体来说,我们将使用 SEER 跟踪并分析目录树中文件访问彼此之间的“距离”有多远。例如,如果文件 f 被打开,然后在跟踪中下一个重新打开(在打开任何其他文件之前),则目录树中这两个打开之间的距离为零(因为它们是同一文件)。如果打开目录 dir中的文件 f(即 dir/f),然后打开同一目录中的文件 g(即 dir/g),则两个文件访问之间的距离为 1,因为它们共享同一目录但不是同一文件。换句话说,我们的距离度量衡量的是您必须在目录树上走多远才能找到两个文件的共同祖先;它们在树中越近,度量越低。
下图显示了在 SEER 集群中所有工作站的 SEER 跟踪中在所有跟踪的整体上观察到的局部性。该图沿 x 轴绘制差异指标,并沿 y 轴显示具有该差异的文件打开的累积百分比。具体来说,对于 SEER 跟踪(图中标记为“Trace”),您可以看到大约 7% 的文件访问是针对先前打开的文件,而近 40% 的文件访问是针对同一文件或到同一目录中的一(即相差零或一)。因此,FFS 局部性假设似乎是有意义的(至少对于这些痕迹而言)。
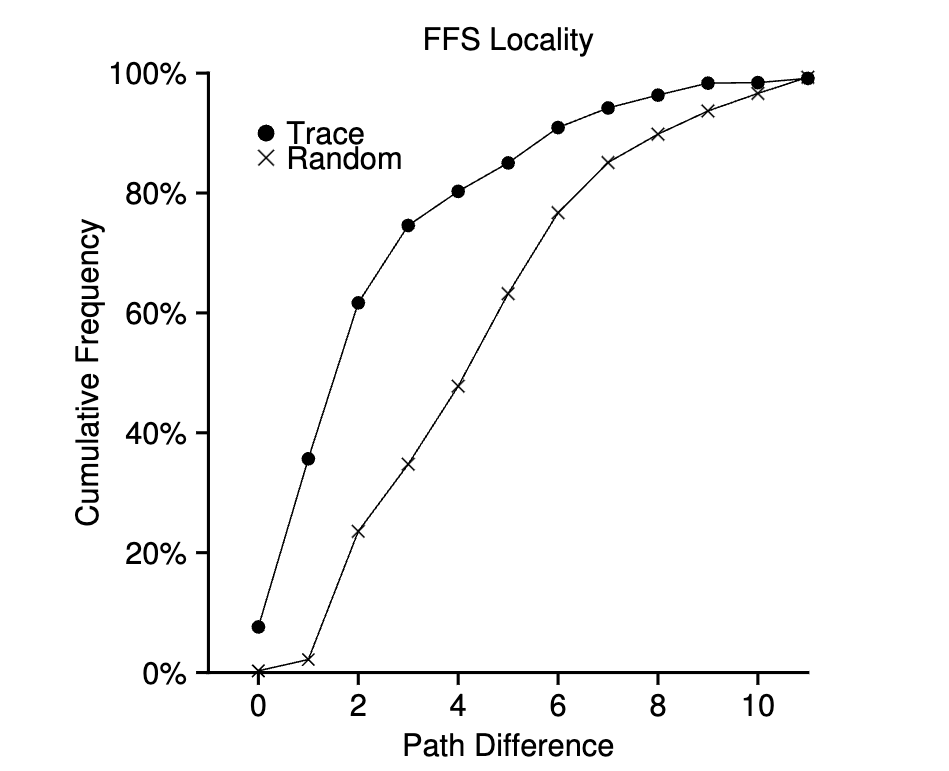
有趣的是,另外 25% 左右的文件访问是针对距离为 2 的文件的。当用户以多级方式构建一组相关目录并在它们之间持续跳转时,就会发生这种类型的局部性。例如,如果用户有一个 src 目录并将目标文件(.o 文件)构建到 obj 目录中,并且这两个目录都是主目录 proj 的子目录,则常见的访问模式将是 proj/src/foo .c 后跟 proj/obj/foo.o。这两个访问之间的距离是 2,因为 proj 是共同的祖先。 FFS 不会在其策略中捕获这种类型的局部性,因此在此类访问之间会发生更多的查找。
为了进行比较,该图还显示了“随机”轨迹的局部性。随机跟踪是通过以随机顺序从现有 SEER 跟踪中选择文件并计算这些随机排序的访问之间的距离度量来生成的。正如您所看到的,正如预期的那样,随机跟踪中的命名空间局部性较少。然而,因为最终每个文件共享一个共同的祖先(例如根),所以存在一些局部性,因此随机作为比较点是有用的。
6 大文件例外
在 FFS 中,文件放置的一般策略有一个重要的例外,那就是大文件。如果没有不同的规则,一个大文件就会占满它第一次放置的块组(也许还有其他块组)。以这种方式填满一个块组是不可取的,因为这会阻止后续的 “相关 “文件被放置在这个块组中,从而可能会损害文件访问的本地性。
因此,对于大文件,FFS 的做法如下。在第一个块组中分配了一定数量的块之后(例如 12 个块,或一个 inode 中可用的直接指针的数量),FFS 会将文件的下一个 “大 “块(例如第一个间接块指向的那些块)放到另一个块组(可能是为了降低利用率而选择的)中。然后,文件的下一个块被放到另一个不同的块组中,依此类推。
让我们通过一些图表来更好地理解这一策略。如果没有大文件例外情况,单个大文件就会将其所有块放入磁盘的一个部分。我们以一个文件 (/a) 为例进行研究,该文件有 30 个块,FFS 配置为每个组 10 个 inodes 和 40 个数据块。下面是没有大文件例外情况的 FFS 的描述:

如图所示,/a 填满了group 0 中的大部分数据块,而其他组仍然是空的。如果现在在根目录 (/) 中创建了其他文件,那么组中就没有太多空间来存放它们的数据了。
在大文件例外情况下(此处设置为每个块中包含五个块),FFS 会将文件分散到各个组中,因此任何一个组内的利用率都不会太高:

你可能注意到,将文件块分散到磁盘上会降低性能,尤其是在相对常见的顺序文件访问情况下(例如,用户或应用程序按顺序读取 0 到 29 块)。但您可以通过谨慎选择块大小来解决这个问题。
具体来说,如果块的大小足够大,文件系统就会花大部分时间从磁盘传输数据,而只花(相对较少的)时间在块的各块之间查找。这种通过增加每次开销的工作量来减少开销的过程称为摊销,是计算机系统中的一种常用技术。
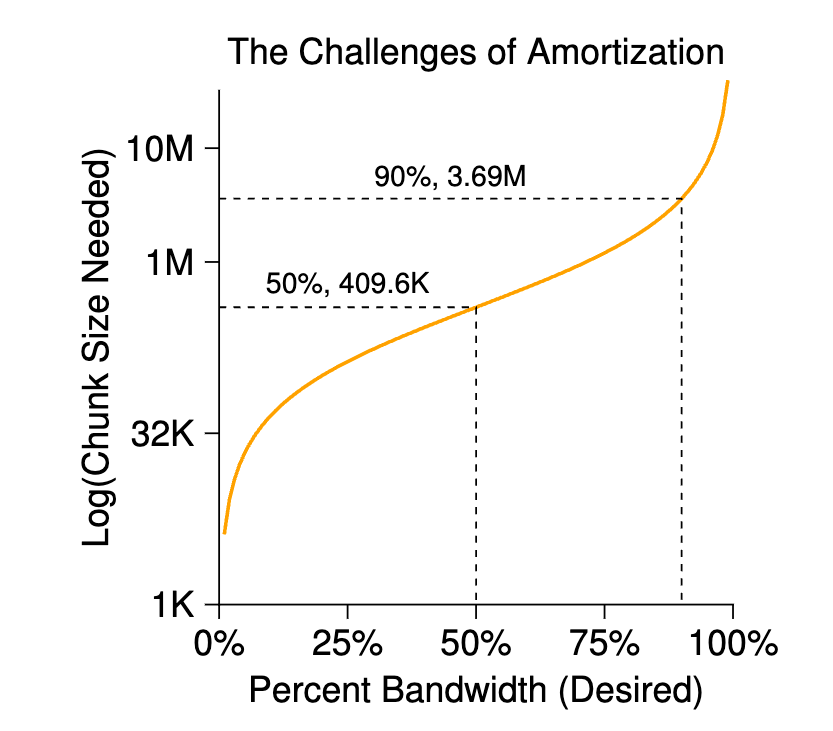
让我们举个例子:假设磁盘的平均定位时间(即寻道和旋转)为 10 毫秒。再假设磁盘的数据传输速度为 40 MB/s。如果您的目标是将一半时间用于在数据块之间寻道,一半时间用于传输数据(从而达到磁盘峰值性能的 50%),那么每 10 毫秒的定位时间就需要花费 10 毫秒来传输数据。那么问题来了:一个数据块需要多大才能花费 10 毫秒来传输数据?我们来计算一下: $$ \frac{40\cancel{MB}}{\cancel{sec}}\cdot\frac{1024KB}{1\cancel{MB}}\cdot\frac{1\cancel{sec}}{1000\cancel{ms}}\cdot10\cancel{ms}=409.6KB $$ 基本上,这个等式表示的是:如果您以 40 MB/s 的速度传输数据,则每次查找时只需传输 409.6KB,以便将一半的时间用于查找,一半的时间用于传输。同样,您可以计算实现 90% 峰值带宽(结果约为 3.69MB),甚至 99% 峰值带宽(40.6MB!)所需的块大小。正如您所看到的,您越接近峰值,这些块就越大(有关这些值如下图所示)。
不过,FFS 并没有使用这种计算方法,以便将大文件分摊到各个组。相反,它根据 inode 本身的结构采取了一种简单的方法。前 12 个直接块与 inode 放在同一个组中;随后的每个间接块及其指向的所有块则放在不同的组中。对于 4KB 的块大小和 32 位磁盘地址,此策略意味着文件的每 1024 个块 (4MB) 被放置在单独的组中,唯一的例外是直接指针指向的文件的第一个 48KB。

请注意,磁盘驱动器的发展趋势是,传输速率的提高相当快,因为磁盘制造商善于将更多bit压缩到相同的表面,但与寻道有关的驱动器机械方面(磁盘臂速度和旋转速度)的提高却相当缓慢。这意味着,随着时间的推移,机械成本会变得相对更昂贵,因此,为了摊销这些成本,你必须在两次寻道之间传输更多的数据。
7 关于 FFS 的其他一些事情
FFS 还引入了其他一些创新。特别是,设计者们非常担心小文件的容纳问题;事实证明,当时许多文件的大小都在 2KB 左右,使用 4KB 的块虽然有利于传输数据,但空间效率却不高。因此,对于一个典型的文件系统来说,这种内部碎片会导致大约一半的磁盘空间被浪费。
FFS 设计者的解决方案很简单,也很好地解决了这个问题。他们决定引入子块,即文件系统可以分配给文件的 512 字节的小块。这样,如果你创建了一个小文件(比如 1KB 大小),它将占用两个子块,从而不会浪费整个 4KB 的块。随着文件的增大,文件系统将继续为其分配 512 字节的块,直到获得完整的 4KB 数据。这时,FFS 会找到一个 4KB 的块,将子块复制到其中,然后释放子块以备将来使用。
你可能会认为这个过程效率很低,需要文件系统做大量额外的工作(尤其是执行复制时需要大量额外的 I/O)。因此,FFS 通常通过修改 libc 库来避免这种低效行为;该库会对写入内容进行缓冲,然后以 4KB 的分块形式将其发送到文件系统,从而在大多数情况下完全避免了子块特殊化。
FFS 引入的第二项重要功能是优化磁盘布局以提高性能。在那个时代(SCSI 和其他更现代的设备接口出现之前),磁盘的复杂程度要低得多,需要主机 CPU 以更实际的方式控制其运行。当文件被放置在磁盘的连续扇区上时,FFS 就会出现问题,如下图左侧所示。

特别是在顺序读取时出现问题。FFS 会首先发出对 0 号块的读取;当读取完成后,FFS 再发出对 1 号块的读取时,为时已晚:1 号块已经在磁头下方旋转,现在读取 1 号块将会导致完全旋转。
FFS 采用不同的布局解决了这个问题,如上图右侧所示。通过跳过每一个其他块(在示例中),FFS 有足够的时间在下一个块经过磁头之前请求下一个块。事实上,FFS 很聪明,它能计算出特定磁盘在布局时应跳过多少块,以避免额外的旋转;这种技术被称为参数化,因为 FFS 会计算出磁盘的特定性能参数,并利用这些参数来决定准确的交错布局方案。
你可能会想:这个方案毕竟没那么好。事实上,使用这种布局,你只能获得峰值带宽的 50%,因为你必须绕每个磁道两次,才能读取每个区块一次。幸运的是,现代磁盘要聪明得多:它们会在内部读入整个磁道,并将其缓冲到内部磁盘缓存中(因此通常称为磁道缓冲区)。这样,在后续读取磁道时,磁盘就会从缓存中返回所需的数据。因此,文件系统不再需要担心这些令人难以置信的低级细节。如果设计得当,抽象和更高级别的接口可能是件好事。
此外,还增加了其他一些可用性改进。FFS 是最早允许使用长文件名的文件系统之一,从而使文件系统中的文件名更具表现力,而不是传统的固定大小方法(如 8 个字符)。此外,文件系统还引入了一个新概念,即符号链接。硬链接的局限性在于它们不能指向目录(因为担心会在文件系统层次结构中引入循环),而且只能指向同一卷内的文件(即 inode number必须仍然有意义)。符号链接允许用户创建指向系统中任何其他文件或目录的 “别名”,因此更加灵活。FFS 还引入了用于重命名文件的原子 rename() 操作。除基本技术外,易用性方面的改进也为 FFS 赢得了更多用户。
相关内容
 支付宝
支付宝 微信
微信